A Primer on Scalability, Concurrency, and Parallelism
Published on
This guide provides a comprehensive overview of the core concepts related to building scalable and performant applications. We will explore the differences between concurrency and parallelism, and dive deep into the main techniques used to achieve them: threading, multiprocessing (workers), and asynchronous programming.
The goal is to provide a solid mental model for how these concepts work, their trade-offs, and when to apply each one effectively.
Table of Contents
- The Building Blocks: Processes and Threads
- Concurrency vs. Parallelism: An Important Distinction
- Task Types in Practice: CPU vs. I/O with Real-World Examples
- Implementation Deep Dive: Threading
- Implementation Deep Dive: Multiprocessing (Workers)
- Implementation Deep Dive: Asynchronous Programming
- Choosing the Right Tool: A Practical Guide
- Real-World Deployment Architectures
- Language Concurrency Models: Python vs. Node.js vs. Go
- Deep Dive: The Python Global Interpreter Lock (GIL)
- Genuine Limitations and Common Pitfalls
1. The Building Blocks: Processes and Threads
Before we can talk about concurrency or parallelism, we need to understand the fundamental units of execution that an operating system (OS) manages: processes and threads.
What is a Process?
Think of a process as a running application. When you double-click an application icon (like your web browser), you're asking the OS to start a new process.
Key characteristics of a process:
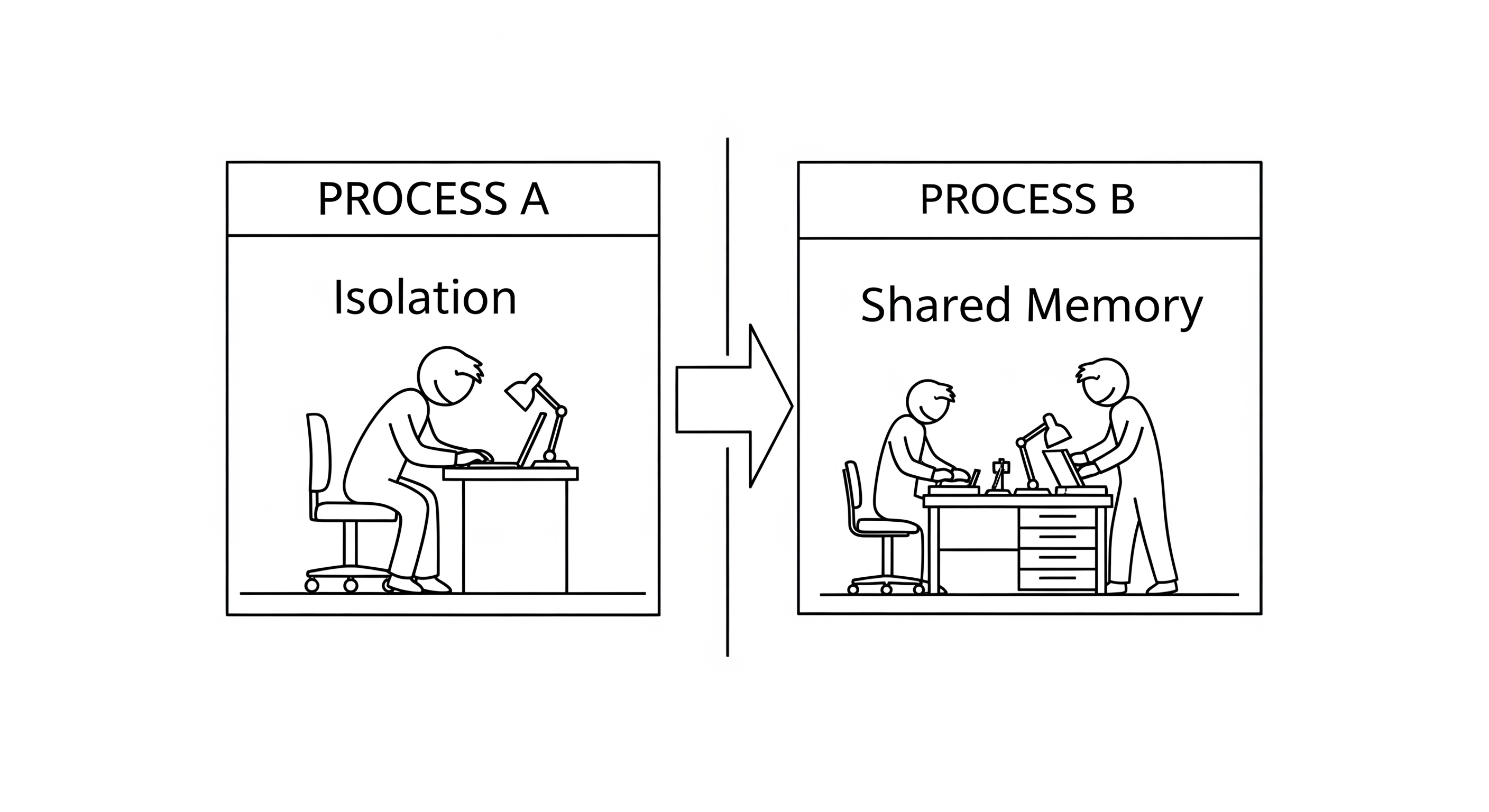
- Isolation: Each process has its own private, isolated memory space. The memory of one process cannot be directly accessed by another. This is a crucial security and stability feature. If one application crashes, it doesn't bring down the entire system.
- Resources: The OS allocates resources to a process, such as memory, file handles, and network sockets.
- Self-Contained: It contains all the instructions and data the program needs to run.
This isolation is powerful, but it also means that sharing information between processes is more complex. This is called Inter-Process Communication (IPC) and requires explicit mechanisms like pipes, sockets, or shared memory files.
Analogy: A process is like a chef working in their own private kitchen. They have their own ingredients (memory), their own stove and tools (resources), and are completely separate from other chefs in other kitchens.
What is a Thread?
A thread is the smallest unit of execution within a process. A process can have one or more threads, which are often called "lightweight processes".
Key characteristics of a thread:
- Shared Memory: All threads within a single process share the same memory space. This means they can read and write to the same variables and data structures easily.
- Shared Resources: They also share the same file handles and other resources owned by the parent process.
- Independent Execution: Each thread has its own instruction pointer and call stack, allowing it to execute instructions independently of other threads in the same process.
Because they share memory, communication between threads is fast and simple. However, this is also their biggest danger. If multiple threads try to modify the same variable at the same time, it can lead to race conditions and corrupted data. This requires careful synchronization using tools like locks or mutexes.
Analogy: Threads are like multiple assistant cooks working in the same kitchen. They all share the same ingredients (memory) and tools (resources). They can work together on the same recipe, but they need to coordinate carefully to avoid getting in each other's way (e.g., "I'm using the salt now, don't touch it!").
The Global Interpreter Lock (GIL) - A Special Case for Python
In the context of Python (specifically the most common implementation, CPython), there's a critical limitation for threading called the Global Interpreter Lock (GIL).
The GIL is a mutex (a type of lock) that ensures only one thread can execute Python bytecode at a time, even on a multi-core processor.
- Why does it exist? It simplifies memory management in CPython and makes it easier to integrate non-thread-safe C libraries.
- What is the impact? It means that for CPU-bound tasks (heavy calculations), using multiple threads in Python will not result in true parallelism. You won't see a performance increase by spreading a calculation across multiple threads, because the GIL will only let one of them run at any given moment.
- Is threading useless in Python? Not at all! The GIL is released when a thread is waiting for I/O (like a network request or reading a file). This makes threading in Python an excellent choice for I/O-bound tasks.
With this foundation, we can now move on to understanding how these processes and threads are used to achieve concurrency and parallelism.
2. Concurrency vs. Parallelism: An Important Distinction
The terms "concurrency" and "parallelism" are often used interchangeably, but they describe two different concepts. Understanding the difference is critical to choosing the right scalability model.
Concurrency: Managing Multiple Tasks
Concurrency is about dealing with many things at once. It's a way of structuring your program to handle multiple tasks that can start, run, and complete in overlapping time periods. However, it doesn't mean they are necessarily running at the exact same instant.
Think about a baker juggling two tasks: baking a cake and making a coffee.
- Preheat the oven (start task 1).
- While the oven is heating, grind the coffee beans (start task 2).
- Put the cake batter in the oven (continue task 1).
- While the cake is baking, brew the coffee (continue task 2).
The baker is handling two tasks concurrently. They are making progress on both in the same time period by switching between them. They are interleaving the execution of the tasks. A single person (or a single-core CPU) can achieve concurrency.
Key idea: Concurrency is about managing context switching. It's a structural concept.
On a single core, tasks are interleaved, not executed simultaneously.
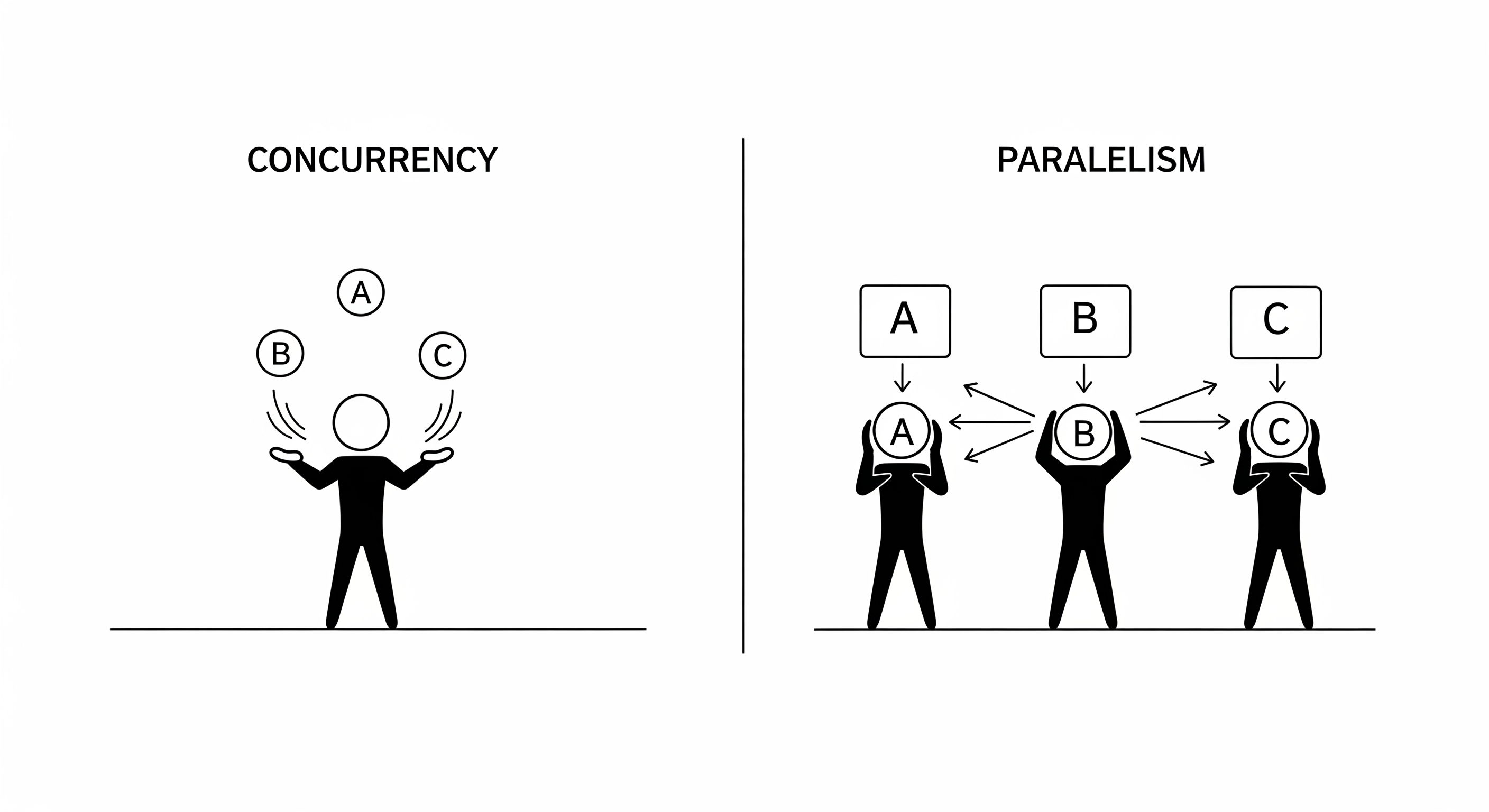
Parallelism: Doing Multiple Tasks
Parallelism is about doing many things at once. It means that multiple tasks are actively executing at the very same instant. This is impossible without hardware that supports it, specifically a multi-core processor.
Now, imagine our baker gets a helper.
- Baker: Preheats the oven and prepares the cake batter.
- Helper: Simultaneously, grinds coffee beans and brews the coffee.
Here, two independent workers (like two CPU cores) are making progress on their tasks at the same time. This is parallelism.
Key idea: Parallelism is about simultaneous execution. It's a hardware-dependent concept.
On multiple cores, tasks can run in parallel, at the same exact time.
The Relationship: A Detailed Breakdown
Concurrency and Parallelism are not mutually exclusive. The tools we use—threading, multiprocessing, and async—are the mechanisms to achieve them.
-
Concurrency is the goal; threading and async are ways to achieve it.
- When you have a single CPU core, you can still have concurrency. An async event loop manages multiple I/O-bound tasks by switching between them when one is waiting. Similarly, the OS can switch between different threads, interleaving their execution. In both cases, you are structuring your code to handle multiple tasks at once.
- Practical Example: A Python
asyncioprogram on a single core that downloads 100 websites. It concurrently manages 100 network requests, but only one bit of Python code is ever running at any given moment.
-
Parallelism is the goal; multiprocessing and threading are ways to achieve it.
- To achieve true parallelism, you need hardware with multiple cores, and you need to run your code on them simultaneously. Multiprocessing is the clearest way to do this. Each process runs on a separate core, achieving parallelism.
- Threading can also achieve parallelism. On a 4-core CPU, the OS can schedule 4 different threads to run on the 4 different cores at the exact same time. (This is true for languages like Java, C++, and Go, but remember the GIL prevents this for CPU-bound tasks in Python).
- Practical Example: A video encoding program uses multiprocessing to split a video into 4 chunks and encodes each chunk on a separate core of a 4-core CPU. The work happens in parallel, finishing roughly 4 times faster.
-
You can, and often do, have both.
- This is the key to modern application architecture. You use parallelism to take advantage of all CPU cores, and you use concurrency within each parallel unit to handle many tasks efficiently.
- Practical Example: A modern web server uses multiprocessing to start a worker process on each CPU core (parallelism). Each of those worker processes then runs an async event loop to handle thousands of simultaneous network connections (concurrency).
Now that we understand the core difference, let's look at the types of problems each model is designed to solve.
3. Task Types in Practice: CPU vs. I/O with Real-World Examples
The distinction between CPU-bound and I/O-bound tasks is the single most important factor in choosing the right concurrency model. Let's break this down with practical examples to make it crystal clear.
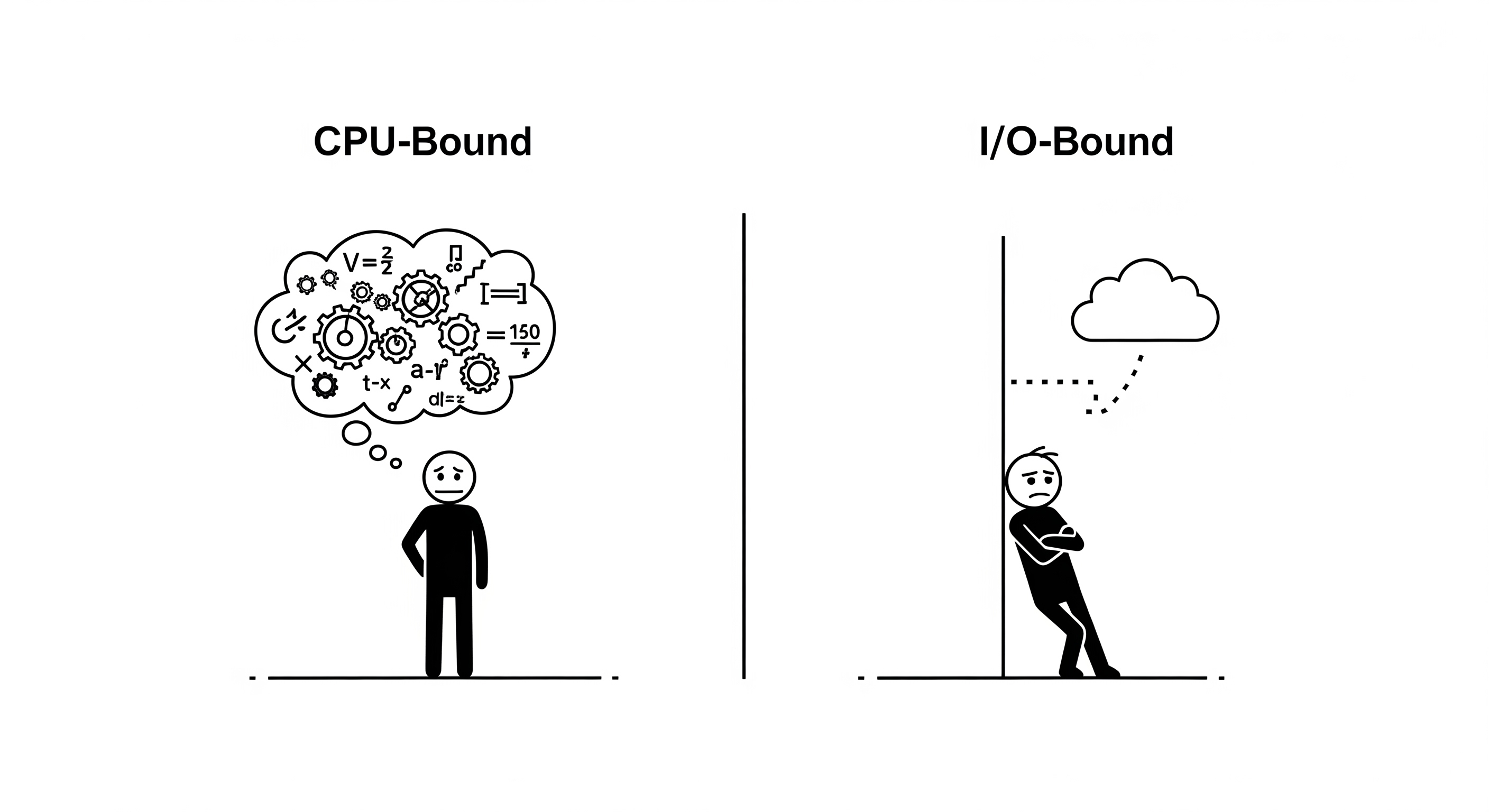
The Chef and the Waiter Analogy
Imagine a high-end restaurant with a single, brilliant Chef (the CPU) and a single Waiter (the I/O channel).
- The Chef is incredibly fast at his work: chopping, mixing, cooking. When he is working, he needs 100% of his focus. This is CPU work.
- The Waiter is responsible for everything outside the kitchen: taking orders, fetching wine from the cellar, getting deliveries from suppliers. This is I/O work. The waiter is often just waiting for things to happen.
Type 1: CPU-Bound Tasks (The Chef is Working)
A task is CPU-bound if the Chef is the bottleneck. The task requires constant, active calculation, and its speed depends only on how fast the Chef can work.
Real-World Analogy: The Chef is given a complex, 100-step recipe to prepare a sauce. He doesn't need to wait for any ingredients. He just works, step-by-step, for 30 minutes straight. The only way to make this faster is to get a faster Chef.
Practical Python Examples:
-
Sorting a large array:
large_list.sort()orsorted(large_list).- Why it's CPU-bound: The processor must constantly compare elements and swap them in memory. There is no waiting for external resources. It's pure computation.
-
Image Processing: Resizing a 10,000x10,000 pixel image.
- Why it's CPU-bound: The CPU has to calculate the new pixel values for the entire new image. It's a massive number of mathematical operations.
-
Data Compression: Compressing a large file into a
.ziparchive.- Why it's CPU-bound: The CPU is executing complex algorithms to find patterns in the data and represent them more efficiently.
-
Financial Modeling: Running a Monte Carlo simulation to predict stock prices.
- Why it's CPU-bound: This involves running thousands or millions of small, randomized calculations. It is pure number-crunching.
For CPU-bound tasks, you need more Chefs (multiprocessing) to get a speedup.
Type 2: I/O-Bound Tasks (The Chef is Waiting for the Waiter)
A task is I/O-bound if the Waiter is the bottleneck. The Chef is fast, but he's constantly waiting for the Waiter to bring him ingredients or for an oven to preheat.
Real-World Analogy: The Chef needs a rare truffle for a dish. He tells the Waiter to go get it. The truffle supplier is across town, so the Waiter is gone for 30 minutes. During this time, the Chef is idle. He is blocked, waiting for the I/O (the truffle delivery) to complete.
Practical Python Examples:
-
Making a Weather API call:
requests.get('https://api.weather.com/...').- Why it's I/O-bound: Your program sends a request over the network. The CPU then does almost nothing. It waits... and waits... for the weather server on the other side of the world to process the request and send back a response. The network latency is the bottleneck, not your CPU.
-
Querying a database:
cursor.execute('SELECT * FROM users WHERE id=123').- Why it's I/O-bound: This is also a network call. Your program sends the query to the database server (which could be on another machine). Your CPU then waits for the database to do its own work (reading from its disk, etc.) and send the result back over the network.
-
Reading a large file from disk:
with open('large_file.txt') as f: data = f.read().- Why it's I/O-bound: Even if the file is on the same machine, the CPU must wait for the physical hard drive or SSD to locate the data and stream it into memory. Modern disks are fast, but they are orders of magnitude slower than a CPU.
For I/O-bound tasks, you don't need more Chefs. You just need to let the Chef work on another dish while the Waiter is out (threading or async).
Clarifying "Blocking I/O"
"Blocking I/O" isn't a type of task; it's a way of handling an I/O-bound task.
-
Blocking (Synchronous): Our Chef tells the Waiter to get the truffle, and then stands at the kitchen door, doing nothing, until the Waiter returns. The entire kitchen is blocked. This is the default behavior in Python. The line
data = requests.get(...)blocks until the response comes back. -
Non-Blocking (Asynchronous): The Chef gives the Waiter a pager. The Chef tells the Waiter to get the truffle and then immediately starts working on another dish. When the Waiter returns, the pager goes off, and the Chef can pause his other work to handle the truffle. This is the model used by
asyncio.
In Python threading, the call is blocking for that one thread (the Chef stands at the door). But because the GIL is released, the interpreter can switch to another thread (a different Chef in a different kitchen who shares the same restaurant) to let them do work.
4. Implementation Deep Dive: Threading
Threading is one of the most common ways to introduce concurrency and (on multi-core systems) parallelism into an application. As we learned, threads are separate execution paths that live within the same process and share the same memory.
How Threading Works
When you spawn a new thread, you are telling the Operating System's scheduler that you have another sequence of instructions you want to run. The OS is then responsible for scheduling time for that thread to run on a CPU core.
On a single-core system, the OS rapidly switches between threads, giving each a small slice of CPU time. This is concurrent execution. On a multi-core system, the OS can assign different threads to different cores, allowing them to run in parallel.
Use Cases: When is Threading a Good Idea?
The primary strength of threading lies in its ability to handle I/O-bound work.
An I/O-bound task is any task where the program spends most of its time waiting for something external, such as:
- Reading or writing a file from a disk.
- Making a network request to an API.
- Querying a database.
While a thread is "blocked" waiting for I/O to complete, the OS can schedule another thread to run. This allows the program to do useful work instead of sitting idle.
Example: Imagine a web scraper that needs to download 100 web pages.
- Synchronous (Single-threaded) approach: Download page 1 (wait), process page 1, download page 2 (wait), process page 2... This is very slow because most of the time is spent waiting for the network.
- Threaded approach: Start 10 threads. Each thread is assigned 10 pages. Thread 1 requests its first page and, while it waits for the download, the OS can run Thread 2, which requests its first page, and so on. The total time is dramatically reduced because all the waiting happens in parallel.
Remember the GIL: In Python, this model works perfectly because the Global Interpreter Lock is released during I/O blocking calls, allowing other threads to run. However, for CPU-bound work (e.g., performing a complex mathematical calculation on the content of the pages), the GIL would prevent threads from running in parallel, and you would see little to no speedup.
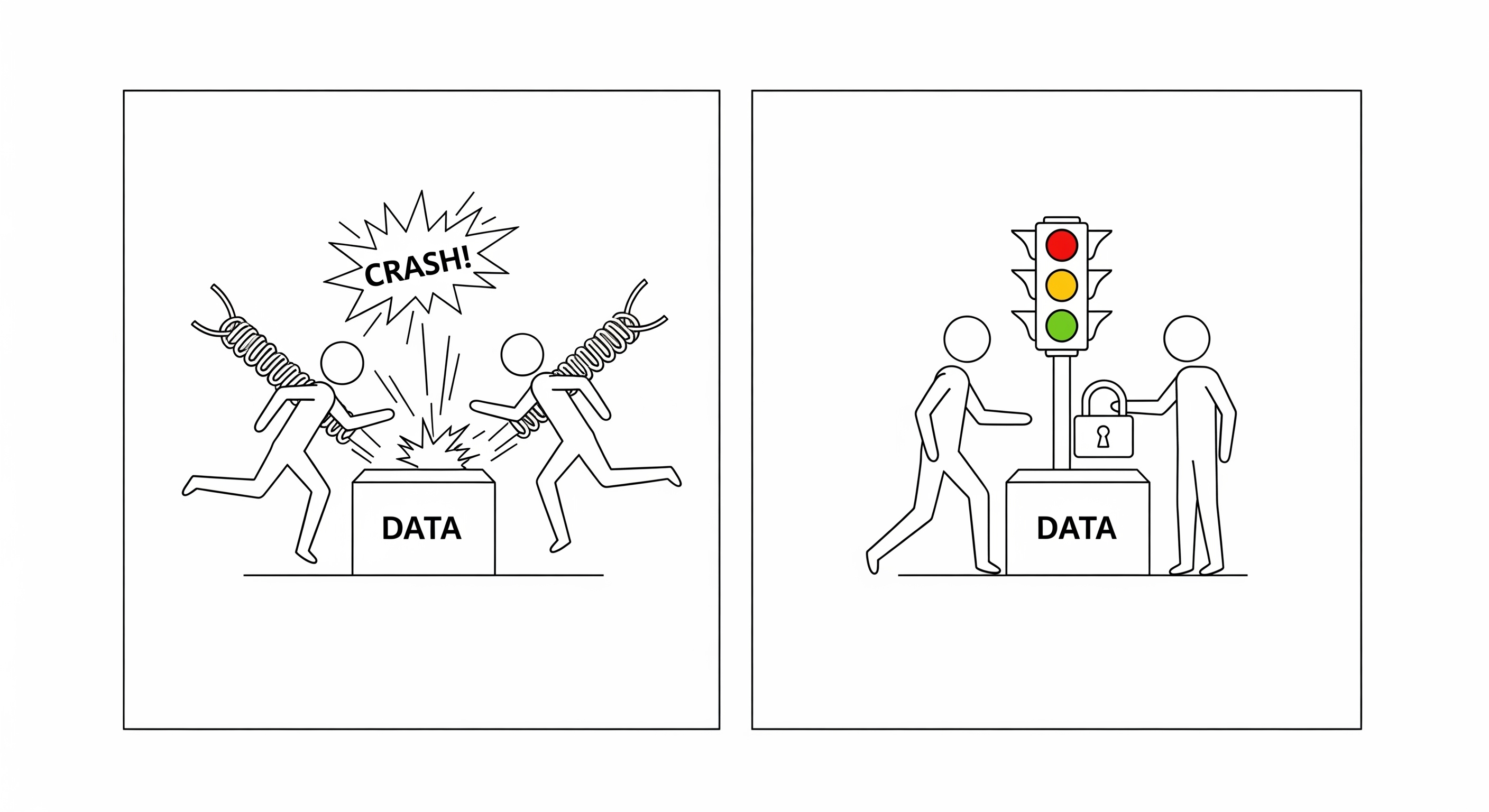
The Dangers of Shared Memory: Race Conditions
The greatest strength of threading—shared memory—is also its greatest weakness. When multiple threads can access and modify the same data, you open the door to a class of bugs called race conditions.
A race condition occurs when the behavior of a system depends on the unpredictable sequence or timing of events.
Classic Example: The Bank Account
Imagine two threads trying to deposit money into the same bank account.
- Initial Balance:
$100 - Thread A wants to deposit
$10. - Thread B wants to deposit
$20. - Expected Final Balance:
$130
Here's how things can go wrong:
- Thread A reads the balance (
$100). - The OS decides to switch context to Thread B.
- Thread B reads the balance (
$100). - Thread B calculates its new balance (
100 + 20 = 120) and writes$120back to memory. - The OS switches back to Thread A.
- Thread A, which is still working with the old balance it read, calculates its new balance (
100 + 10 = 110) and writes$110back to memory.
Final Balance: $110. The deposit from Thread B has been completely lost.
To prevent this, you must use synchronization primitives, like a Mutex or Lock. A lock ensures that only one thread can access a "critical section" of code at a time.
# Pseudocode with a lock
lock.acquire() # Only one thread can get past here
balance = read_balance()
new_balance = balance + deposit_amount
write_balance(new_balance)
lock.release() # Let another thread in
While locks solve the problem, they introduce their own complexities, such as deadlocks (where two threads are each waiting for a lock the other one holds). Managing shared state in a threaded environment is one of the most difficult aspects of concurrent programming.
5. Implementation Deep Dive: Multiprocessing (Workers)
Multiprocessing is a form of parallelism where we run multiple independent processes, often called workers. Unlike threads, which live inside a single process, each worker process has its own memory space and, in Python, its own Global Interpreter Lock (GIL).
This is the most direct way to achieve true parallelism and leverage multiple CPU cores.
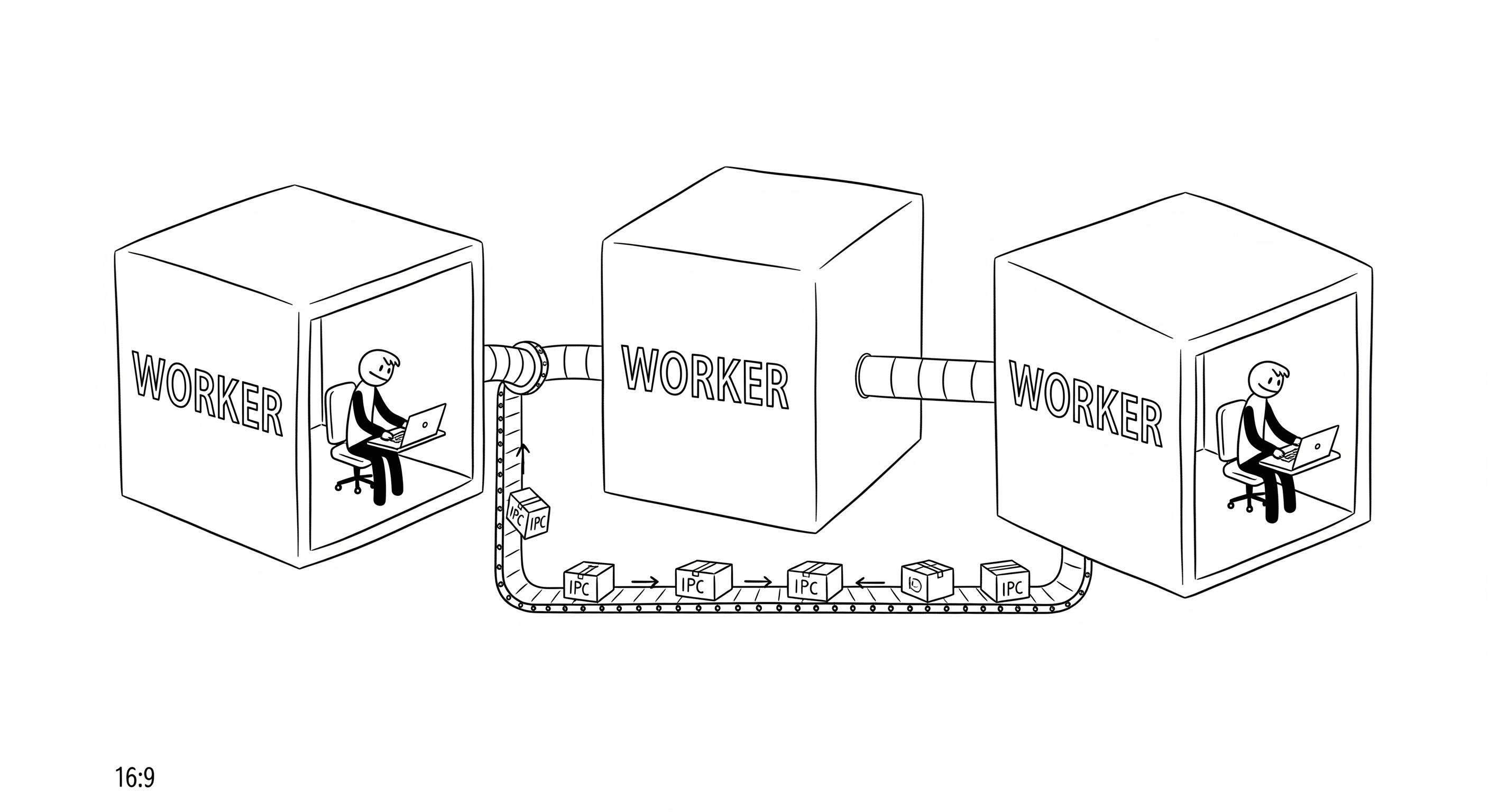
How Multiprocessing Works
When you start a new process, you are asking the OS to create a nearly-complete copy of your main program. This includes its own memory and its own Python interpreter. The OS can then schedule this new process to run on a different CPU core from the parent process.
Because each process has its own memory, there is no risk of the kind of race conditions we see in threading. The memory is isolated. This makes multiprocessing conceptually simpler in some ways—you don't need to worry about locks.
Use Cases: When is Multiprocessing a Good Idea?
Multiprocessing is the go-to solution for CPU-bound tasks.
A CPU-bound task is one where the program spends most of its time performing intensive calculations, and the speed is limited by the CPU's clock speed. Examples include:
- Video encoding or image processing.
- Scientific computing and simulations.
- Data analysis on large datasets (e.g., matrix multiplication).
- Training a machine learning model.
By splitting the workload across multiple processes, you can get a near-linear performance improvement for each additional CPU core you use.
Example: You need to process 1,000 images by applying a complex filter to each.
- Single-process approach: Process image 1, then image 2, then image 3... If each image takes 1 second, this will take 1,000 seconds.
- Multiprocessing approach: You have a 4-core CPU. You start 4 worker processes. You divide the 1,000 images among them, so each worker gets 250 images to process. Since they are all running in parallel on different cores, the total time will be roughly
1000 images / 4 cores = 250 seconds(plus a little overhead).
This is how you sidestep the Python GIL for CPU-intensive work. Since each process has its own interpreter and memory, each has its own GIL, and they don't interfere with each other.
The Trade-offs: Overhead and Communication
The main downside of multiprocessing is its overhead.
- Memory Usage: Creating a new process consumes significantly more memory than creating a new thread, as the OS has to duplicate the process's memory space. Spawning hundreds of processes can quickly exhaust system RAM.
- Startup Time: Processes are slower to start up than threads.
- Inter-Process Communication (IPC): Because memory is not shared, communicating between worker processes is more difficult. You can't just modify a shared variable. Instead, you have to use explicit communication channels provided by the operating system, such as:
- Pipes: A unidirectional communication channel between two processes.
- Queues: A data structure that allows multiple processes to safely add and remove items.
- Shared Memory Blocks: A more advanced technique where you explicitly ask the OS for a block of memory that can be shared between specific processes.
This process of sending data between processes is called serialization (or "pickling" in Python), where Python objects are converted into a byte stream. This adds computational overhead, especially for large objects.
Multiprocessing is a powerful tool for CPU-bound parallelism, but it's heavier than threading. Next, we'll look at a completely different model for concurrency that uses a single thread.
6. Implementation Deep Dive: Asynchronous Programming
Asynchronous programming (or "async") is a model of concurrency that is fundamentally different from threading or multiprocessing. Instead of using multiple threads or processes, async code is able to achieve very high levels of concurrency on a single thread.
It is the foundation of modern, high-performance network applications, like those built with Node.js, or with Python libraries like asyncio and FastAPI.
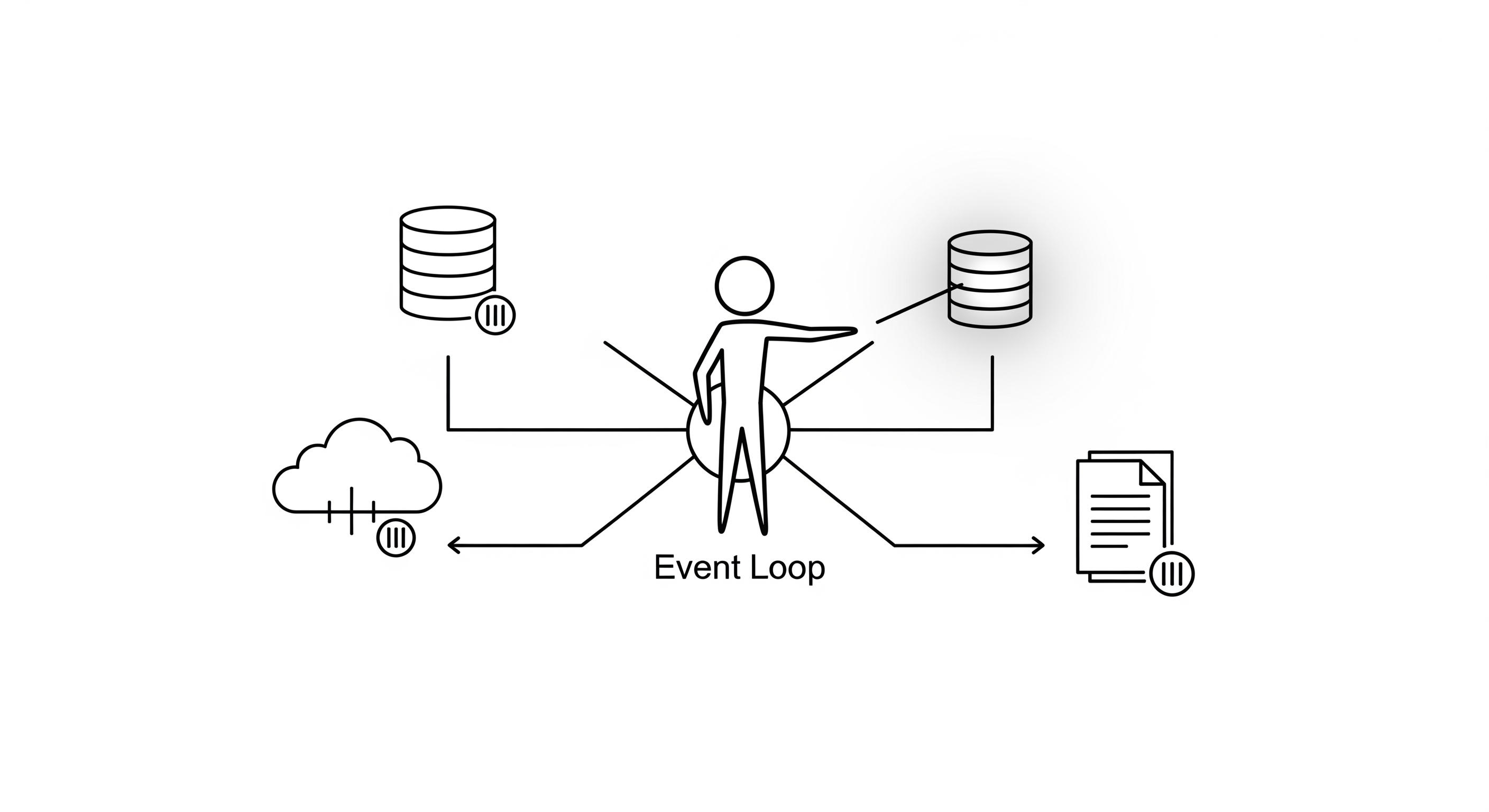
How Asynchronous Programming Works: The Event Loop
The heart of an async system is the event loop. The event loop is a single-threaded process that manages and distributes tasks.
The key idea is non-blocking I/O. In a traditional (synchronous) model, when you make an I/O request (e.g., query a database), your program stops and waits for the response. This is "blocking".
In an async model, when a task makes an I/O request, it doesn't wait. Instead, it tells the event loop, "Hey, I'm going to be waiting for this database query. I'll let you know when it's done. In the meantime, you can run something else."
This is called yielding control. The task gives control back to the event loop, which is then free to run another task that is ready to do work. When the database query is finally finished, the event loop is notified and it will schedule the original task to continue running from where it left off.
This cycle repeats continuously:
- A task runs until it hits an I/O operation.
- It gives control back to the event loop.
- The event loop finds another task that is ready to run and executes it.
- When the I/O operation from the first task is complete, it tells the event loop it's ready again.
- At some point, the event loop picks up the first task again and continues its execution.
async and await: Making it Look Synchronous
Modern languages have developed the async and await keywords to make writing async code much more manageable.
async def(in Python) orasync function(in JavaScript): This marks a function as a "coroutine". It's a special function that can be paused and resumed.await: This is the "magic" keyword. When youawaitsomething (like a network call), you are telling the event loop, "Pause my execution here, and give control back to the event loop. When this I/O operation is finished, resume me."
# Python asyncio example
import asyncio
async def fetch_data(url):
print(f"Starting to fetch {url}")
# In a real app, this would be a non-blocking HTTP request
await asyncio.sleep(2) # Simulate a 2-second network call
print(f"Finished fetching {url}")
return {"data": f"Some data from {url}"}
async def main():
# These tasks are started concurrently
task1 = asyncio.create_task(fetch_data("google.com"))
task2 = asyncio.create_task(fetch_data("twitter.com"))
# 'await' here means "wait for this task to be complete"
result1 = await task1
result2 = await task2
print(f"Got results: {result1}, {result2}")
asyncio.run(main())
In this example, both fetch_data calls will be "in-flight" at the same time. The total runtime will be about 2 seconds, not 4 seconds, because the asyncio.sleep() calls run concurrently.
Use Cases and Trade-offs
Best for: Extremely high-level I/O-bound workloads. Async is king when you have tens of thousands of simultaneous connections (e.g., a chat application, a live-streaming server, or a microservice handling a huge number of API requests).
Why is it better than threading for this?
- Lower Overhead: Creating a new task in an async system is much cheaper than creating a new thread. Threads have a significant memory and scheduling overhead from the OS. Async tasks are managed within the application's event loop. This allows a single process to handle many more concurrent connections.
- No Race Conditions (mostly): Since everything runs on a single thread, you cannot have two pieces of Python code interrupting each other. You don't need locks. The points where the code can be switched (
await) are explicit. This simplifies state management.
The main limitation:
- Doesn't help with CPU-bound work. If you have a task that just crunches numbers for 5 seconds without ever hitting an
await, it will block the entire event loop. No other tasks can run during that time. Async is not a tool for parallelism.
We've now seen the three main approaches. The next step is to synthesize this knowledge into a practical guide for choosing the right one.
7. Choosing the Right Tool: A Practical Guide
We've explored the three primary models for concurrent and parallel programming. Now comes the most important question: which one should you use?
The answer almost always depends on the nature of the problem you are trying to solve. The key is to first identify the bottleneck in your task. Is it limited by the CPU, or is it limited by waiting for I/O?
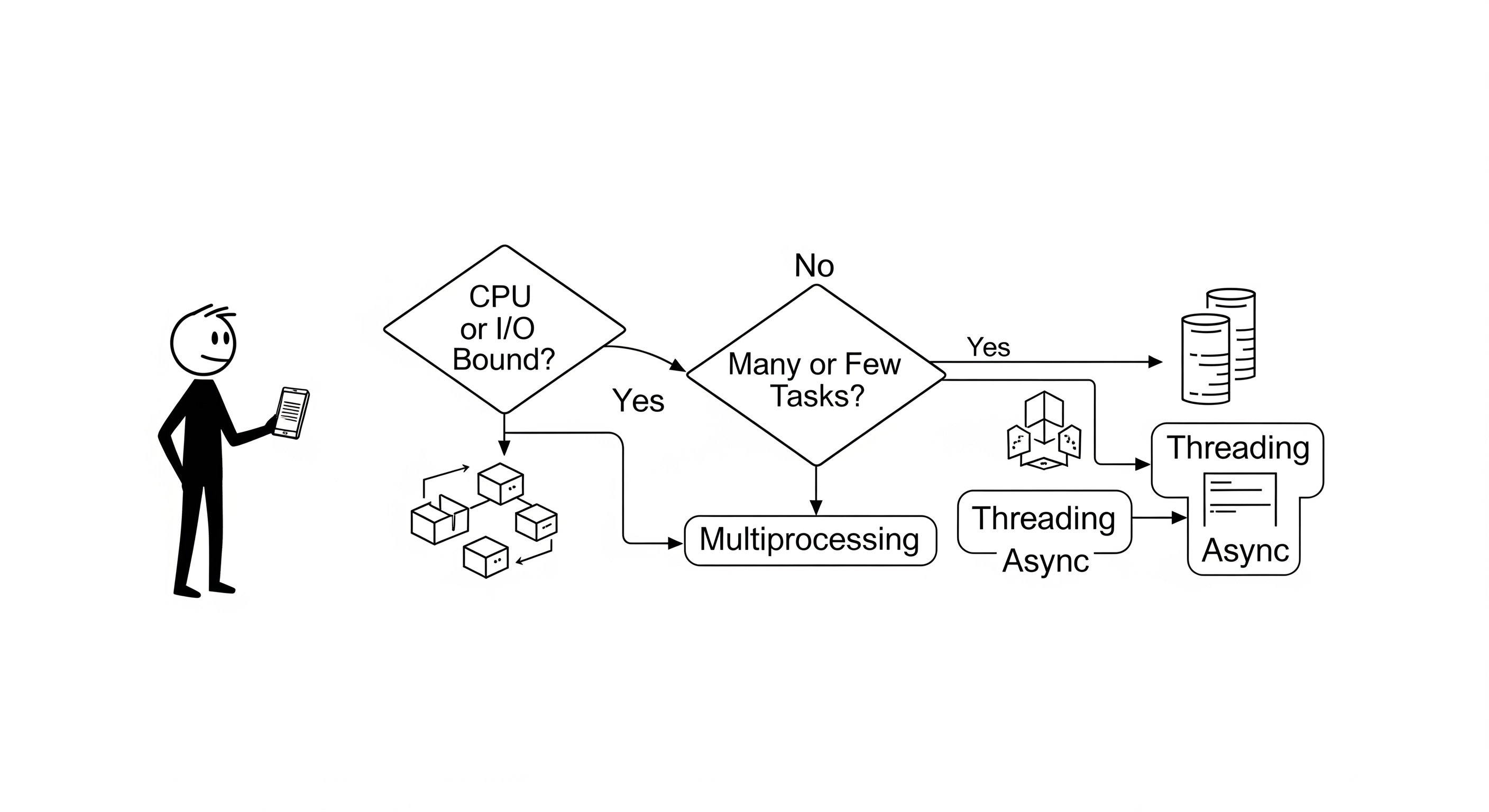
The Decision Flowchart
Here is a simple mental model to help you decide.
graph TD
A[Start: What kind of task is it?] --> B{Is the task CPU-bound?};
B -- Yes --> C[Use Multiprocessing];
B -- No (It's I/O-bound) --> D{How many concurrent connections/tasks?};
C --> G[Goal: True parallelism for calculations.<br/>Bypass the GIL.<br/>Benefit from multiple cores.];
D -- "A few to a few hundred" --> E[Use Threading];
D -- "Many thousands" --> F[Use Async];
E --> H[Goal: Simplicity for moderate I/O.<br/>Good for existing synchronous codebases.<br/>Overlapping I/O wait times.];
F --> I[Goal: Massive I/O concurrency.<br/>Lowest memory overhead per task.<br/>Ideal for network services.];
subgraph Legend
direction LR
CPU(CPU-Bound: Math, Image Processing, ML)
IO(I/O-Bound: API Calls, DB Queries, File Read/Write)
end
style G fill:#d4edda,stroke:#c3e6cb
style H fill:#d1ecf1,stroke:#bee5eb
style I fill:#fff3cd,stroke:#ffeeba
1. Is your task CPU-bound?
This is the first and most important question.
- Yes, it's CPU-bound: Your task involves heavy computation, simulations, data transformation, etc. The answer is almost always Multiprocessing. You need to leverage multiple CPU cores to get real performance gains, and in languages like Python, this is the only way to bypass the GIL for parallel computation.
- No, it's I/O-bound: Your task spends most of its time waiting for network requests, database responses, or disk operations. Proceed to the next question.
2. (For I/O-bound tasks) How many concurrent operations do you need?
-
A few to a few hundred: If you're managing a reasonable number of concurrent tasks (e.g., a web scraper for a small site, a backend handling a moderate number of users), Threading is often a great choice. It's conceptually simple for many developers, as you can often take a synchronous piece of logic and just wrap it in a thread. The OS handles the scheduling, and the overhead is acceptable at this scale.
-
Many thousands or more: If you're building a system that needs to handle a massive number of simultaneous, long-lived connections (e.g., a chat server, a real-time bidding platform, an IoT data collector), Asynchronous Programming is the superior choice. The low memory and CPU overhead of async tasks compared to threads becomes critical at this scale. A threaded server would likely fall over from resource exhaustion long before an async server would.
Hybrid Approaches: The Best of Both Worlds
You don't always have to choose just one. Many of the most scalable systems use a hybrid approach.
A common pattern for a modern Python web server (like one running FastAPI or Django) is:
- Multiprocessing: Start a main process that forks several worker processes, typically one per CPU core (e.g., using a process manager like Gunicorn). This provides true parallelism.
- Asynchronous: Within each of those worker processes, run an async event loop (e.g., using Uvicorn). This allows each worker to handle thousands of incoming network requests concurrently.
This model scales both vertically (using all cores on a single machine) and horizontally (by adding more machines). It uses multiprocessing to solve the CPU-bound problem (leveraging all cores and bypassing the GIL) and async to solve the I/O-bound problem (handling many connections efficiently).
With this framework, you can now analyze your specific problem and make an informed decision. The final step is to understand the real-world limits you might hit.
8. Real-World Deployment Architectures
Let's see how the concepts of concurrency and parallelism apply to common production deployment setups. This is where theory meets practice.
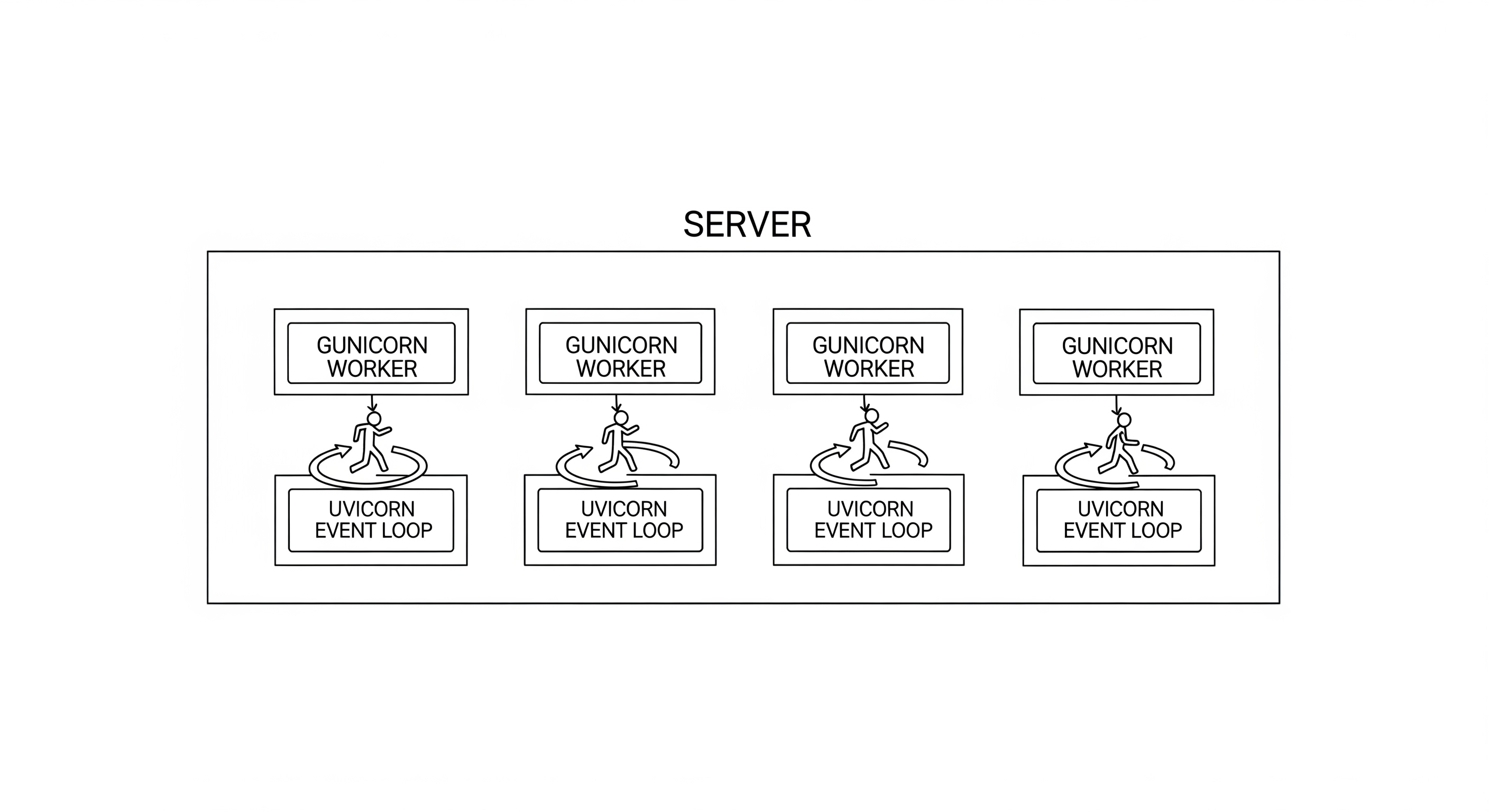
1. Python: FastAPI with Gunicorn & Uvicorn Workers
This is the canonical example of the hybrid "Parallelism + Concurrency" model.
- The Setup: You have a FastAPI application, which is built on
asyncio. You use a process manager like Gunicorn to run it. A typical command might begunicorn my_app:app --workers 4 --worker-class uvicorn.workers.UvicornWorker. - Multiprocessing (Parallelism): Gunicorn starts by creating a master process. This master process then forks itself 4 times, creating 4 independent "worker" processes. If your server has 4 CPU cores, the OS will schedule one worker process per core. This is parallelism. Your application is now capable of using all 4 cores simultaneously.
- Async (Concurrency): The
--worker-class uvicorn.workers.UvicornWorkerpart tells each Gunicorn worker to run using Uvicorn, which is an ASGI server that understandsasyncio. Within each of the 4 worker processes, a single-threaded async event loop is running. This event loop can handle thousands of I/O-bound requests concurrently. - How it Handles a Long-Running Agent Session:
- A user request comes in to start an agent session. A load balancer directs it to one of the 4 Gunicorn workers (e.g., Worker 2).
- The
asynccode in your FastAPI application on Worker 2 handles the request. Let's say the agent needs to make an API call to OpenAI (a classic I/O-bound operation). - Worker 2's event loop sees the
await openai.Completion.acreate(...)call. It starts the network request and immediately yields control. - While waiting for OpenAI's response, Worker 2's event loop is free. It can now handle hundreds of other incoming requests for other users, perhaps starting their own I/O-bound operations or finishing ones whose data has returned.
- When the OpenAI response for the first user arrives, the event loop picks up that original task and continues executing it.
This architecture is extremely scalable. The parallelism from Gunicorn lets you saturate your CPU cores, while the concurrency from asyncio lets each core handle a massive number of simultaneous connections, all without being blocked by slow networks.
2. JavaScript: Next.js on Vercel
This architecture demonstrates "managed parallelism" in a serverless environment.
- The Setup: You write a Next.js application. Each page or API route can be defined as a Serverless Function. You deploy this to a platform like Vercel.
- How it Works (Parallelism): When a request comes in for a specific page (e.g.,
/dashboard), Vercel doesn't have a server constantly running your code. Instead, it spins up an execution environment (like a tiny virtual machine or container), runs the function for your/dashboardpage, and returns the result. - If 100 users hit your
/dashboardpage at the same time, Vercel's infrastructure will automatically provision 100 parallel execution environments to handle them. You don't manage the processes; the cloud platform does it for you. This is a powerful form of on-demand parallelism. - Concurrency within the function: Each individual serverless function is a Node.js environment, which runs an async event loop. If your
/dashboardfunction needs to fetch data from 3 different external APIs to build the page, it can make those 3 network requests concurrently usingasync/await. This minimizes the execution time (and thus the cost) of that single function invocation.
This model abstracts away the need for process managers like Gunicorn. You focus on the application logic, and the platform provides the parallelism as needed.
Now that we've seen how these concepts are applied in the wild, let's compare how different programming languages approach concurrency at a fundamental level.
9. Language Concurrency Models: Python vs. Node.js vs. Go
The way a language handles concurrency is a fundamental part of its design and philosophy. While we have focused on Python, comparing it to other popular backend languages like Node.js and Go reveals different approaches to the same problems.
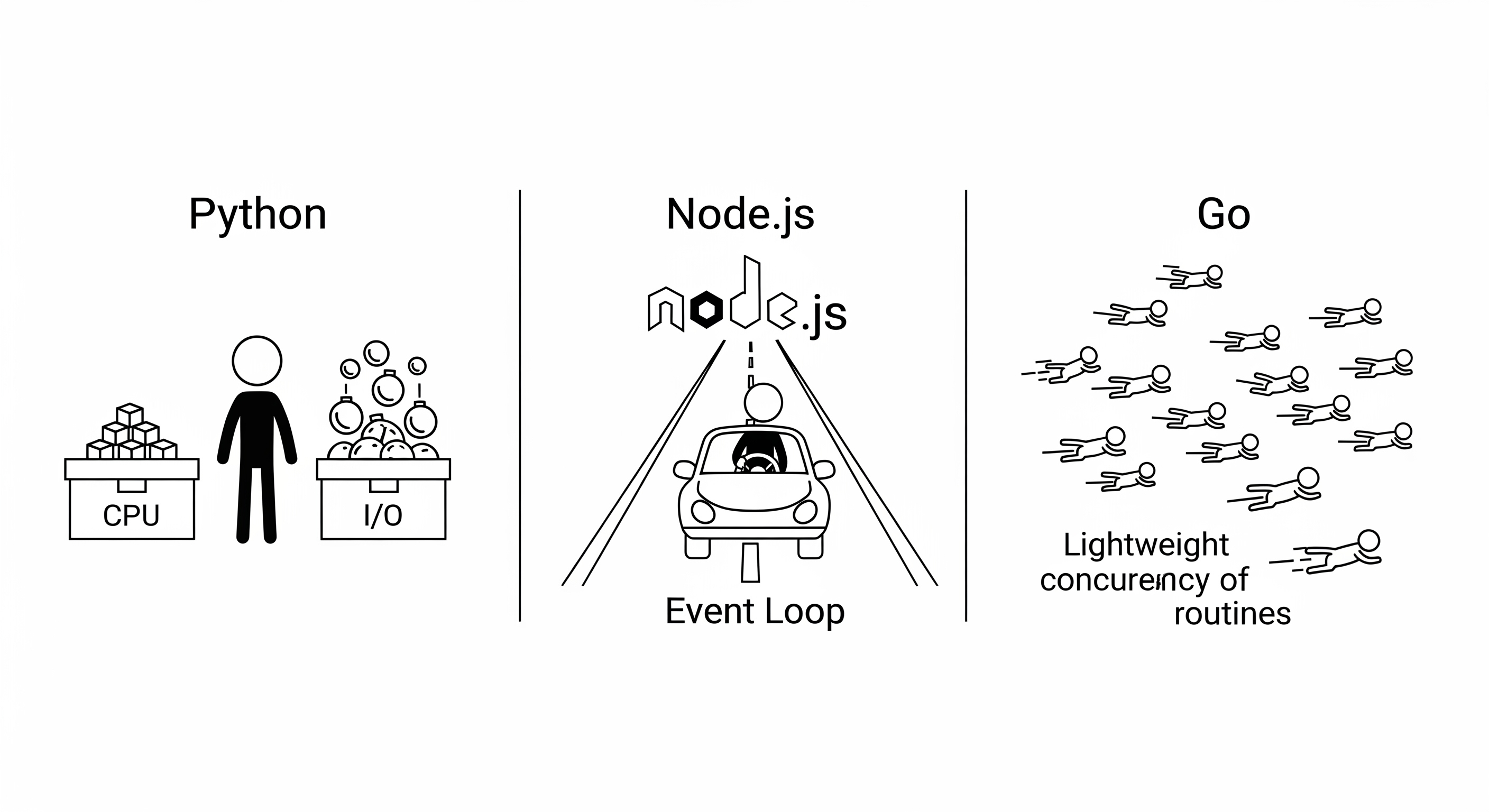
Python: The Pragmatist's Hybrid Model
- Core Model: Python offers two distinct tools for two distinct problems. It uses preemptive multitasking where the Operating System is in charge of scheduling threads.
- Multiprocessing for CPU-bound tasks.
- Threading or Asyncio for I/O-bound tasks.
- Mechanism:
- Threads: OS-level threads. Heavyweight. Good for moderate I/O concurrency. Their CPU parallelism is defeated by the Global Interpreter Lock (GIL).
- Processes: OS-level processes. Very heavyweight. The only way to achieve true CPU-parallelism in CPython, as each process gets its own memory and GIL.
- Asyncio: Cooperative multitasking. A single thread runs an event loop, and tasks explicitly yield control with
await. Very lightweight. Best for massive I/O concurrency.
- Philosophy: "Here are all the tools. Pick the right one for your specific job." This is powerful and flexible but places the burden on the developer to understand the problem's nature (CPU vs. I/O) and choose correctly.
Node.js: The I/O Specialist
- Core Model: A single-threaded, event-driven, non-blocking I/O model. It is the epitome of the asynchronous pattern.
- Mechanism:
- The Event Loop: The heart of Node.js. All of your JavaScript code runs on a single main thread. When you initiate an I/O operation (e.g., a database query), you provide a callback function (or use a
Promise/async/await). The request is handed off to a highly optimized C++ library (libuv) that manages the I/O in the background. - When the I/O is complete, libuv places the corresponding callback into an event queue. The event loop continuously checks this queue and executes the callbacks on the main thread.
- The Event Loop: The heart of Node.js. All of your JavaScript code runs on a single main thread. When you initiate an I/O operation (e.g., a database query), you provide a callback function (or use a
- Nuances & Comparison:
- Similarity to Python's
asyncio: The model is almost identical. If you understandasyncio, you understand the Node.js event loop. - Brilliant for I/O: It's designed from the ground up for I/O-bound workloads and can handle tens of thousands of simultaneous connections with minimal memory overhead.
- Terrible for CPU-Bound Work: A long-running, synchronous CPU-bound calculation in your JavaScript code will block the entire event loop. Since there is only one main thread, the entire application becomes unresponsive. No other requests can be processed.
- Achieving Parallelism: For CPU-bound tasks, Node.js provides a
worker_threadsmodule, which is analogous to Python'sthreadingbut without a GIL. More commonly, developers run multiple Node.js processes using a tool like PM2 or the built-inclustermodule. This is identical to Python's multiprocessing approach.
- Similarity to Python's
Go: Concurrency as a First-Class Citizen
- Core Model: A highly efficient, baked-in concurrency model based on Communicating Sequential Processes (CSP).
- Mechanism:
- Goroutines: Extremely lightweight, application-level threads. They are not OS threads. The Go runtime manages them. You can easily spawn hundreds of thousands or even millions of goroutines.
- Go Scheduler: The Go runtime has a powerful M:N scheduler. It multiplexes M goroutines onto N OS threads. This means it can effectively use all available CPU cores without the developer having to think much about it. It will run multiple goroutines in parallel on different cores.
- Channels: The preferred way for goroutines to communicate. Instead of sharing memory and using locks (like threads), you pass messages between goroutines through channels. This makes concurrent code safer and easier to reason about.
- Nuances & Comparison:
- No GIL: Go was designed for modern multi-core processors from day one. There is no GIL.
- Solves Both CPU and I/O Problems: Because the scheduler can run goroutines on any OS thread, Go is excellent for both CPU-bound and I/O-bound work out of the box. If a goroutine makes a blocking I/O call, the scheduler simply moves the other goroutines on that OS thread to a different, non-blocked OS thread and continues executing them.
- Different Paradigm: The learning curve can feel steeper if you are used to threads or async. You have to learn about goroutines, channels, and the
selectstatement. However, the result is often simpler, more robust concurrent code.
Comparison Table
| Feature | Python (CPython) | Node.js | Go |
| | - | -- | -- |
| Primary Model | Multi-paradigm (Threads, Processes, Async) | Single-Threaded Event Loop (Async) | Lightweight Goroutines & Channels (CSP) |
| Best Use Case | General purpose; requires explicit choice | High-volume I/O-bound network services | Mixed I/O and CPU-bound services, high concurrency |
| CPU-Bound Handling | Multiprocessing (to bypass GIL) | Poor; blocks event loop. Use Worker Threads | Excellent; goroutines run in parallel on all cores |
| I/O-Bound Handling | Excellent (via Threading or Asyncio) | Excellent (native event loop) | Excellent (scheduler handles blocking calls efficiently) |
| Key Limitation | The GIL prevents threaded CPU parallelism. | Single thread; a CPU-bound task blocks all. | Different paradigm (channels) can have a learning curve. |
| "Hello World" Concurrency | threading.Thread() or multiprocessing.Process() | fs.readFile('..', callback) or await | go my_func() |
10. Deep Dive: The Python Global Interpreter Lock (GIL)
The Global Interpreter Lock, or GIL, is one of the most discussed and misunderstood concepts in Python. It's a core part of CPython (the standard implementation of Python) that has profound implications for concurrent programming. Let's break down exactly what it is, why it exists, and what it means in practice.

1. What is the GIL, Really? An Effective Explanation
At its core, the GIL is a mutex (a type of lock) that protects access to Python objects, preventing multiple threads from executing Python bytecode at the same time within a single process.
To understand this, let's use a better analogy than just a simple lock. Think of the Python interpreter as a single, highly valuable, and delicate resource—let's call it the "Python Magic Object". To interact with this object (i.e., to execute any Python code), a thread must be holding the "Talking Stick". The GIL is this Talking Stick. There is only one Talking Stick per Python process.
If a thread has the Talking Stick, it can run its Python code. If another thread wants to run, it must wait until the first thread puts the Talking Stick down.
Why is this protection needed? Memory Management.
CPython's memory management relies on a mechanism called reference counting. Every object in Python has a counter that tracks how many variables are pointing to it. When a new variable references an object, its count increases. When a reference is removed, its count decreases. When the count reaches zero, the object's memory is freed.
This system is simple and efficient, but it is not "thread-safe." Imagine this scenario without a GIL:
- An object's reference count is 1. Thread A and Thread B both have access to it.
- Thread A decides to get rid of its reference. It reads the reference count (value: 1).
- Context Switch! The OS pauses Thread A and switches to Thread B.
- Thread B also decides to get rid of its reference. It reads the reference count (value: 1).
- Thread B calculates the new count (
1 - 1 = 0), writes the value 0 back, and, seeing the count is zero, frees the memory associated with the object. - Context Switch! The OS switches back to Thread A.
- Thread A was already in the middle of its operation. It, too, calculates the new count (
1 - 1 = 0), writes the value 0 back, and tries to free the memory... which has already been freed by Thread B.
This is a "double free" error, a classic memory corruption bug that can cause your program to crash unpredictably. The GIL prevents this by ensuring that Thread A's entire "read-calculate-write" operation is atomic. It holds the Talking Stick for the whole procedure, so Thread B can't interfere.
2. What Does "Integrating Non-Thread-Safe C Libraries" Mean?
Python's power comes from its vast ecosystem of third-party libraries. Many of the most popular libraries (like NumPy, Pillow, and SciPy) are not written in pure Python. They are C programs with a Python interface, often called C extensions.
Many of these C libraries were written long before multi-core CPUs were common. They were designed for single-threaded execution and often rely on global or static variables for their internal state. They are not thread-safe, meaning that if you call functions from two different threads at the same time, they could corrupt this internal state, leading to chaos.
How the GIL helps:
By enforcing that only one thread can be executing Python bytecode at a time, the GIL provides a blanket guarantee to these C extensions. If your Python code calls into a C extension, you can be sure that no other thread will be calling into it at the same time. The GIL essentially "protects" these C libraries without them needing to implement their own complex and difficult-to-maintain locking mechanisms.
This made it incredibly easy for developers to wrap existing C libraries and make them available in Python. This ease of integration was a primary driver of Python's adoption in fields like scientific computing and data science, contributing massively to its success. The GIL was a pragmatic choice that prioritized ease of C integration and single-threaded performance.
3. Why Threading Isn't Useless for I/O-Bound Tasks
This is the most crucial point to understand. The GIL seems like it cripples threading, but it doesn't for I/O-bound tasks. The key is that threads can, and do, release the GIL.
A thread holds the GIL only when it is actively executing Python bytecode (doing CPU work). When a thread encounters an operation that will take a while and does not involve running Python code—like waiting for a network response, querying a database, or reading a large file from disk—it performs a blocking I/O call.
The CPython interpreter is smart about this. Before it makes the system call to the operating system to perform the I/O, the thread releases the GIL.
Let's refine our analogy:
- Imagine a single librarian (the GIL) at a desk, and 10 students (threads) who each need to retrieve a book from a vast, slow, automated archive (the I/O operation).
- Student 1 walks up, takes the librarian's attention, and fills out a request form (a tiny bit of CPU work). The librarian processes the request and sends it to the archive. The librarian tells Student 1, "This will take a while. Go wait over there." The librarian is now free.
- Student 2, who was waiting, immediately steps up to the now-free librarian and submits their request form. The librarian sends it to the archive and tells Student 2 to go wait.
- This continues for all 10 students.
Now, all 10 students are "concurrently" waiting for their books from the archive. The "work" of waiting is happening in parallel. As soon as a book arrives for any student, the librarian calls them back to the desk to receive it.
This is exactly how Python threading works for I/O. One thread makes a network request and releases the GIL. While it's waiting, the interpreter switches to another thread, which runs its Python code until it also makes an I/O request and releases the GIL. The result is that you can have many threads "waiting" for I/O at the same time, dramatically reducing the total runtime. The program is only ever blocked if all threads are simultaneously trying to do CPU work, which is rare in an I/O-bound application.
4. How is the GIL Release Controlled and Kept Safe?
This is a critical point. A thread doesn't just release the GIL randomly; that would cause chaos. The release is explicit and deliberate, happening only in specific, well-defined circumstances.
The rule is: The GIL is released on operations that are "external" to the Python interpreter's execution loop, specifically when a thread must wait for the Operating System.
Think of it as a contract. The Python interpreter promises to hold the GIL whenever it is touching Python objects or executing Python bytecode. But when it hands control over to the OS kernel for a potentially long wait, it releases the GIL so another thread can use the interpreter.
-
What is a "purely external" operation? This is any system call that causes the thread to sleep in the OS kernel. The most common examples are I/O operations: reading from a network socket, writing to a disk, or waiting on a database connection. The code for these operations lives inside the OS, not the Python interpreter. When Python asks the OS to
read(socket), the OS takes over, and the Python interpreter is free to release the GIL and let another thread run. Once the OS has data ready, it wakes the original thread, which then waits to re-acquire the GIL before processing the data it received. -
What about CPython library interactions? If a C extension needs to perform a long-running operation without interacting with Python objects, it can—and should—manually release the GIL. The
numpylibrary does this. When you perform a large matrix multiplication, the C code innumpycan release the GIL, perform the intense calculation on its own (outside the world of Python objects), and then re-acquire the GIL to hand the result back to Python. This allows a CPU-boundnumpycalculation in one thread to run in parallel with another thread doing other work. However, if a C extension is poorly written and doesn't release the GIL, it will block the entire interpreter, just like pure Python CPU-bound code.
The conflict you're worried about is avoided because the GIL is only released when control is passed to a part of the system (the OS kernel or a carefully written C extension) that does not touch Python's internal state.
5. Key Definitions in Context
Let's clearly define these core concepts both generally and in the context of the GIL.
CPU-Bound
- General Meaning: A task whose performance is limited by the speed of the processor. It spends its time performing computations (e.g., mathematical operations, data processing). The task is "bound" by how fast the CPU can execute instructions.
- In the Context of the GIL: A thread performing a CPU-bound task in pure Python is executing Python bytecode nonstop. Because of this, it holds the GIL continuously and does not release it. This is why running multiple threads for a purely CPU-bound Python task gives no performance benefit; only one thread can ever be running at any given moment.
I/O-Bound (Input/Output Bound)
- General Meaning: A task whose performance is limited by waiting for input/output operations to complete. The CPU is often idle, waiting for a much slower peripheral device (like a network card or a hard drive) to send or receive data.
- In the Context of the GIL: This is where threading is useful. When a thread starts an I/O operation (e.g.,
requests.get(url)), it is making a blocking I/O call. The CPython interpreter releases the GIL just before this call, allowing other threads to run. The "waiting" happens in parallel, so the total time is drastically reduced.
Blocking I/O
- General Meaning: A programming paradigm where a function call that performs I/O will block the execution of its thread until the I/O operation is complete. If you call
data = file.read(), that line of code will not return, and the next line will not execute, until all the data from the file has been read. - In the Context of the GIL: This is the key to understanding Python threading. Even though the call is "blocking" for the thread that made it, the interpreter's release of the GIL unblocks all other threads in the process. This is the magic trick: one thread blocks, but the program as a whole remains responsive. This is distinct from asynchronous programming, which uses non-blocking calls that return immediately, managing the waiting in an event loop.
11. Genuine Limitations and Common Pitfalls
Understanding the theoretical models is one thing; applying them successfully requires an awareness of their real-world limitations and the common traps developers fall into. No model offers infinite scalability.
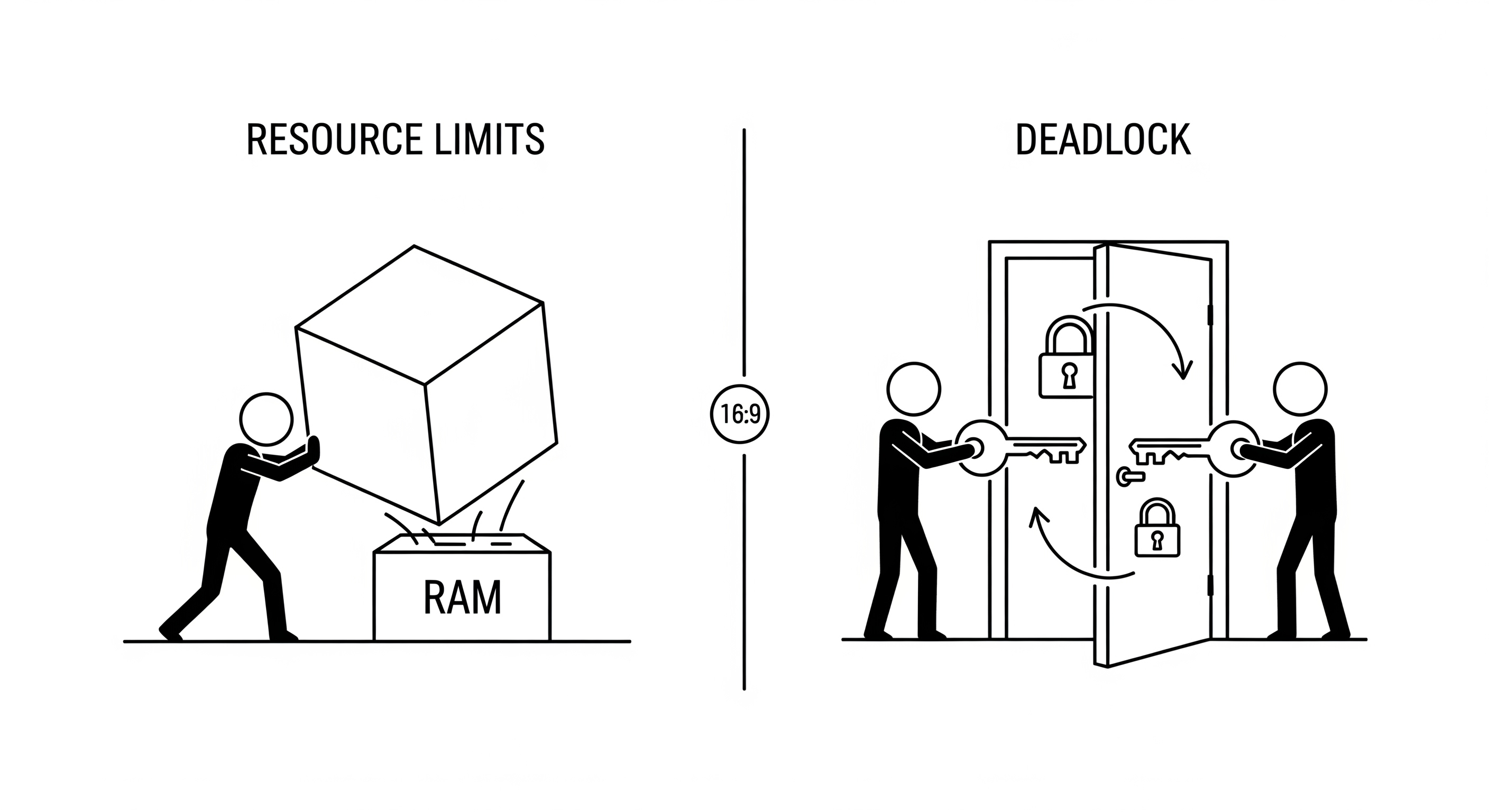
Hardware and Physical Limitations
-
Number of CPU Cores: This is the most fundamental limit to parallelism. You cannot run more tasks in true parallel than you have physical CPU cores. If you have 8 cores, you can run 8 CPU-bound tasks at 100% simultaneously. Spawning a 9th process for a CPU-bound task won't make it faster; the OS will have to context-switch between at least two of the processes on a single core.
-
Memory (RAM): Every process and every thread consumes memory.
- Processes are memory-heavy. If a single process takes 500MB of RAM, starting 16 of them will require 8GB of RAM, not including OS overhead. You can easily exhaust system memory by creating too many worker processes.
- Threads are lighter but not free. Each thread requires its own stack space (often 1-8MB). Spawning thousands of threads can also lead to memory exhaustion.
- Async tasks have the smallest memory footprint, which is why they scale so well for I/O-bound work.
-
I/O Throughput: Your application's speed can be limited by the hardware it's waiting on.
- Network Bandwidth: If your 100-thread web scraper is running on a slow internet connection, adding more threads won't help if the network pipe is already saturated.
- Disk Speed: A program writing huge amounts of data can be limited by the write speed of the hard drive (SSD vs HDD).
- Database Connections: Databases often have a limit on the number of concurrent connections they will accept. If your 1000-thread application tries to open 1000 database connections at once, the database itself will become the bottleneck and start rejecting them. Connection pooling is a common pattern to mitigate this.
Language and Runtime Limitations
-
The Global Interpreter Lock (GIL): As we've discussed, the GIL in CPython is a major limitation, effectively serializing the execution of CPU-bound Python code, rendering threading useless for parallelizing such tasks. This is a prime example of a runtime-specific constraint.
-
OS File Handle Limits: Operating systems limit the number of open files a single process can have. Since network connections are often treated like files, a high-traffic server can hit this limit, leading to "Too many open files" errors. This limit can usually be adjusted in the OS configuration.
The Complexity Pitfalls of Concurrency
These are not performance limitations, but conceptual traps that make concurrent programming notoriously difficult.
-
Race Conditions: The classic bug where the outcome depends on the unpredictable timing of thread execution. This is solved with locks, but locks themselves introduce other problems.
-
Deadlocks: A situation where two or more threads are stuck forever, waiting for each other.
- Thread A locks resource
Xand is waiting to lock resourceY. - Thread B has already locked resource
Yand is now waiting to lock resourceX. - Neither thread can proceed. The program freezes.
- Thread A locks resource
-
Starvation: A thread is "starved" when it is perpetually denied the resources it needs to run, often because other "greedier" threads are monopolizing them.
-
Complexity of Debugging: Debugging concurrent applications is hard. Bugs may be non-deterministic, appearing only under specific, rare timing conditions. It's difficult to reproduce them consistently, making them a nightmare to find and fix.
The Golden Rule: The best way to manage the complexity of concurrency is to avoid sharing state whenever possible. The less data your threads or processes have to share and modify, the fewer opportunities there are for race conditions and deadlocks. This is why the multiprocessing model (with its isolated memory) and the async model (with its single-threaded nature) can often be simpler to reason about than complex, multi-threaded applications with lots of shared data.
This concludes the guide on scalability, concurrency, and parallelism. By understanding the building blocks, the different models, and their real-world limitations, you are now much better equipped to design and build robust, performant, and scalable software.