How I Built Git Version Control From Scratch In GO
Published on

This guide is an architectural case study of sidgit-go, a Git implementation built from first principles in Go. It is designed for engineers who are new to Go but familiar with version control concepts. We will not just build a tool; we will deconstruct an existing, production-ready system to understand the engineering rationale behind its design.
Through a focused deep dive into the critical path of a version control system, you will learn the "why" behind the code—the architectural trade-offs, the data structures, and the algorithms that make systems like Git possible.
Table of Contents
- The Problem With Version Control
- System Architecture: A High-Level Overview
- The Content-Addressed Object Store
- Trees and the Index: From Files to Directory Snapshots
- Commits, Pointers, and the Directed Acyclic Graph
- Building a Commit Graph Visualizer
- Conclusion and Next Steps
Prerequisites
- Go: Intermediate proficiency. Understanding of structs, interfaces, and basic concurrency.
- Git: Basic user-level familiarity.
- Systems Design: A desire to understand the internal architecture of distributed systems.
The Problem With Version Control: A Systems Engineering Perspective
The Engineering Challenge: Managing State in Distributed, Asynchronous Systems
Before we deconstruct the architecture of a version control system (VCS), it is critical to define the engineering problem it is designed to solve. A modern VCS is not merely a tool for saving files; it is a distributed system for managing state transitions in a complex, asynchronous environment. The core challenge is to maintain data integrity and provide a coherent history when multiple agents (developers) are modifying a shared state (the codebase) concurrently.

This complexity manifests in three primary dimensions: time, collaboration, and scale.
Dimension 1: The Problem of Time (State Management & History Traversal)
Software is a living entity; its state evolves with every line of code changed. Without a VCS, managing this temporal state is an exercise in manual, error-prone bookkeeping. This introduces significant operational risk.
Scenario Analysis: Imagine a web service with a critical authentication bug in production. The codebase has undergone 50 changes since the last stable release. The engineering challenge is to perform a root cause analysis with maximum efficiency to minimize Mean Time to Resolution (MTTR).
- Without a VCS: The process is a manual binary search through file backups (e.g.,
app-v1.zip,app-v2.zip). This is computationally inefficient, lacks context, and is operationally untenable. A developer might spend hours comparing files manually with no guarantee of finding the root cause efficiently, leading to extended service degradation. - With a VCS: The process is a single command:
git bisect. The VCS automates the search, identifying the breaking change in O(log n) time, where n is the number of commits. This is a powerful demonstration of a system designed for efficient history traversal.
This is not a matter of convenience; it is a matter of production stability and operational excellence. The inability to efficiently traverse the history of a codebase is a direct threat to operational uptime and a violation of modern SRE principles.
Dimension 2: The Problem of Collaboration (Concurrent State & Distributed Systems)
Software development is a distributed, asynchronous process. Multiple engineers often work on the same codebase simultaneously, leading to the classic distributed systems problem of managing concurrent state without a central locking mechanism.
Scenario Analysis:
Two engineers, Alice and Bob, are working on the same file, auth.js, in separate feature branches.
- Alice adds a new function,
validateJWT(). - Bob refactors an existing function,
hashPassword().
Without a VCS, their work must be integrated manually. This process, often done via email or shared drives, is fraught with risk:
- Lost Updates: Bob might accidentally overwrite Alice's changes, a classic race condition.
- Logical Conflicts: Their changes might be technically mergeable but logically incompatible, leading to subtle runtime errors that bypass unit tests.
A modern VCS solves this with a structured, three-way merge algorithm. It provides a formal, automatable process for integrating concurrent changes, flagging conflicts at the line level and preserving a complete, auditable history of the integration. This is a fundamental requirement for any collaborative engineering effort.
Dimension 3: The Problem of Scale (Codebase Integrity & Cryptographic Guarantees)
As a codebase grows to millions of lines of code and hundreds of contributors, ensuring its integrity becomes a paramount challenge. How can we be certain that the files on a developer's machine are identical to the files in the central repository, bit for bit?
Scenario Analysis: A critical security library is updated to patch a zero-day vulnerability. The change is distributed to a team of 50 engineers. How can we verify that every engineer has the exact, correct version of the file, free from corruption or accidental modification?
- Without a VCS: This would require manually running checksums (e.g.,
md5sum,sha256sum) on every file on every machine—a process that is both inefficient and rarely performed, leaving significant security gaps. - With a VCS: This is the core function of the content-addressed object model. Every file, directory, and commit is identified by a cryptographic hash (SHA-1). A single
git statuscommand instantly verifies the integrity of the entire working directory against the repository's known state. This provides a constant, low-cost integrity check.
This cryptographic assurance is not a "nice-to-have"; it is a foundational requirement for building secure, reliable software at scale. It transforms the problem of data integrity from a manual, ad-hoc process into an intrinsic property of the system.
Success Criteria for Our VCS
Based on this analysis, our implementation of sidgit-go must satisfy the following engineering requirements:
- Immutable History: The system must cryptographically guarantee the integrity of the codebase's history. Any change to any part of the history must result in a different cryptographic signature for the entire repository.
- Efficient State Traversal: It must provide mechanisms to efficiently inspect, retrieve, and compare any previous state of the codebase.
- Structured Concurrency: It must provide a formal, reliable mechanism for integrating changes from multiple, independent lines of development.
This guide will deconstruct how sidgit-go achieves these goals through its architecture, data structures, and algorithms, providing a comprehensive understanding of the engineering principles behind modern version control systems.
System Architecture: A High-Level Overview
Architectural Blueprint of sidgit-go: A Layered Approach
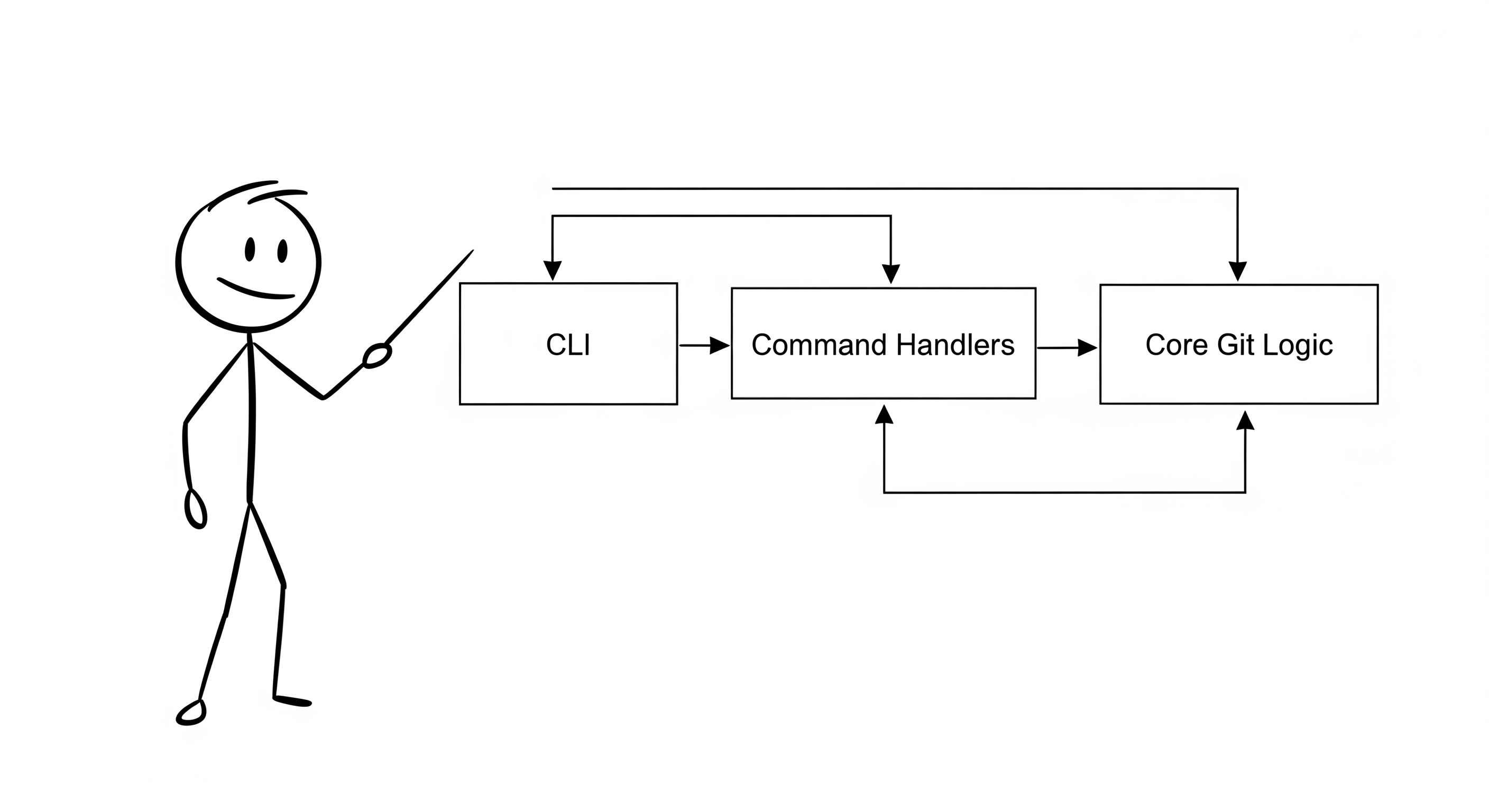
Before we deconstruct the implementation details, it is essential to understand the system's high-level architecture. sidgit-go is designed with a clean, three-layer separation of concerns, a common pattern in robust command-line applications that isolates core domain logic from the user interface. This makes the system easier to maintain, test, and extend.
graph TD
subgraph "Presentation Layer (cmd/sidgit-go)"
A[User Input] --> B{Cobra CLI Framework};
end
subgraph "Application Logic Layer (internal/cli)"
B --> C[Command Handlers];
end
subgraph "Core Domain Layer (internal/git)"
C --> D[Git Logic & Data Structures];
end
subgraph "Data Storage Layer"
D --> E((.sidgit Directory));
end
style A fill:#333,stroke:#888,stroke-width:2px;
style B fill:#444,stroke:#888,stroke-width:2px;
style C fill:#555,stroke:#888,stroke-width:2px;
style D fill:#666,stroke:#888,stroke-width:2px;
style E fill:#777,stroke:#888,stroke-width:2px;
1. Presentation Layer (cmd/sidgit-go)
This layer is the system's entry point, responsible for all user interaction.
- Responsibility: To define the CLI's command structure, including commands (e.g.,
commit), subcommands (branch list), flags (--graph), and argument validation. It is the sole component responsible for parsing raw user input. - Implementation: This layer is built using the Cobra library, a popular framework for building modern CLI applications in Go. Each command has its own file (e.g.,
init.go,add.go) that defines its structure and help text. - Key Insight: The presentation layer is deliberately kept "thin." Its only job is to translate user input into a structured format and route it to the appropriate handler in the application logic layer. It contains no business logic itself. This is a critical design choice that decouples the UI from the core functionality, allowing for future interfaces (e.g., a web UI) to be built on top of the same core logic.
2. Application Logic Layer (internal/cli)
This layer acts as a bridge, translating high-level commands into a sequence of core Git operations.
- Responsibility: To handle the execution of commands. It receives parsed arguments from the presentation layer, orchestrates calls to the core domain layer, manages application-level concerns like concurrency (as seen in
HandleAdd), and formats the output for the user (e.g., color-coded status messages). - Implementation: The
handlers.gofile contains a handler function for each CLI command (e.g.,HandleInit,HandleAdd). These functions act as controllers, managing the flow of data between the presentation and core domain layers. - Key Insight: This layer is where the application's "business logic" resides. For example,
HandleCommitis responsible for retrieving the commit message, finding the parent commit viaHEAD, writing the tree object, creating the commit object, and updating the branch reference. It encapsulates the complete workflow for a given command.
3. Core Domain Layer (internal/git)
This is the heart of the system. It contains a platform-agnostic implementation of Git's data structures and algorithms.
- Responsibility: To manage all direct interactions with the
.sidgitrepository's object database and reference files. This includes reading and writing objects, parsing data structures, managing references, and traversing the commit graph. - Implementation: This layer is organized by Git concepts, providing a clean API for repository operations:
object.go: Handles low-level read/write ofblob,tree, andcommitobjects, including zlib compression/decompression.index.go: Manages the staging area with functions likeReadIndexandWriteIndex.refs.go: Manages branches andHEADpointers with functions likeGetHeadRefandUpdateBranch.tree.go,commit.go: Contains parsing logic for these object types.graph.go: Implements graph traversal algorithms (e.g., topological sort, ancestry checks).
- Key Insight: This layer is a self-contained library that could be imported into any Go application. It is completely independent of the CLI, which is a testament to its robust, modular design.
4. Data Storage Layer (.sidgit directory)
This is the physical manifestation of the repository on the file system, designed for integrity and performance.
- Responsibility: To store all repository data, including objects, references, and configuration, in a manner that is both efficient and cryptographically secure.
- Implementation: A directory structure that mirrors Git's, with subdirectories for
objects(sharded by the first two characters of the SHA-1 hash),refs/heads,refs/tags, etc. All data is stored in a content-addressable format.
By understanding this layered architecture, we can now proceed to deconstruct each component, starting from the core domain layer and working our way up to the user interface, analyzing the engineering decisions made at each step.
The Content-Addressed Object Store
The Cryptographic Foundation of sidgit-go
The bedrock of any Git-like system is its object store. This is not a conventional database; it is a content-addressed key-value store, a design that provides the cryptographic guarantees necessary for a distributed version control system. In this chapter, we will deconstruct the implementation of sidgit-go's object store by analyzing the hash-object and cat-file commands.
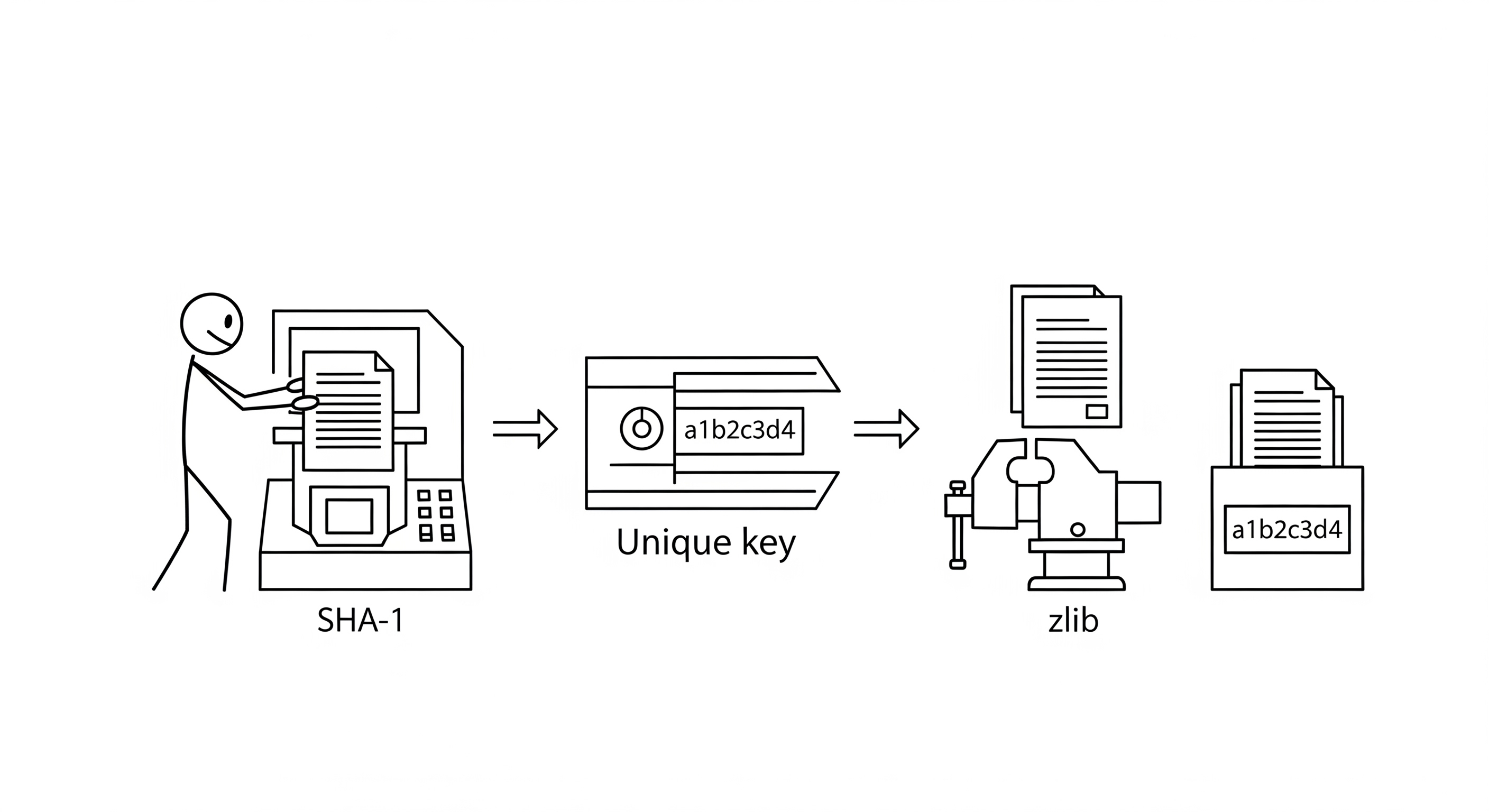
The hash-object Command: Writing to the Object Store
The hash-object command is the most direct way to interact with the object store. It takes a file, computes its hash, and optionally writes it to the database. Let's analyze the core logic from internal/git/object.go.
The WriteObject Function
// internal/git/object.go
func (r *Repository) WriteObject(data []byte, objType string) (string, error) {
// 1. Create the object header: type, length, and a null terminator
header := []byte(fmt.Sprintf("%s %d\x00", objType, len(data)))
// 2. Prepend header to the data
fullContent := append(header, data...)
// 3. Compute the SHA-1 hash of the combined content
hash := sha1.Sum(fullContent)
sha1Str := fmt.Sprintf("%x", hash)
// 4. Determine the object path (sharded by the first two hash characters)
objDir := filepath.Join(r.GitDir, "objects", sha1Str[:2])
objPath := filepath.Join(objDir, sha1Str[2:])
// 5. Create the directory if it doesn't exist
if err := os.MkdirAll(objDir, 0755); err != nil {
return "", err
}
// 6. Compress the content using zlib
var b bytes.Buffer
w := zlib.NewWriter(&b)
w.Write(fullContent)
w.Close()
// 7. Write the compressed content to the file system atomically
return sha1Str, ioutil.WriteFile(objPath, b.Bytes(), 0644)
}
Engineering Rationale:
- Object Header: The header (
blob 12\x00hello world) is crucial. It provides metadata about the object (type and size) and is part of the content that gets hashed. This prevents SHA-1 collisions between different object types with the same content (e.g., abloband atreethat happen to have the same byte sequence). - SHA-1 Hash: The SHA-1 hash serves as the unique key for the object. Because the hash is computed from the content and the header, any change to the file, however small, will result in a completely different SHA-1. This is the cryptographic guarantee of data integrity.
- Directory Sharding: Storing all objects in a single directory would be inefficient for large repositories, as many file systems have performance issues with directories containing millions of files. By sharding the objects into subdirectories based on the first two characters of their SHA-1 hash,
sidgit-goavoids these performance bottlenecks. - zlib Compression: Compressing the content with zlib (RFC 1950) saves disk space, especially for text-based files. This is a standard performance optimization in Git that trades a small amount of CPU time for significant storage savings.
The cat-file Command: Reading from the Object Store
The cat-file command allows us to inspect the contents of any object in the database. Its implementation reveals the reverse process of writing an object.
The ReadObject Function
// internal/git/object.go
func (r *Repository) ReadObject(sha1Str string) (string, []byte, error) {
// 1. Reconstruct the object path from the SHA-1
objPath := filepath.Join(r.GitDir, "objects", sha1Str[:2], sha1Str[2:])
// 2. Read the compressed content from the file system
compressedContent, err := ioutil.ReadFile(objPath)
if err != nil {
return "", nil, err
}
// 3. Decompress the content using zlib
reader, err := zlib.NewReader(bytes.NewReader(compressedContent))
if err != nil {
return "", nil, err
}
defer reader.Close()
decompressed, err := ioutil.ReadAll(reader)
if err != nil {
return "", nil, err
}
// 4. Parse the header and content by finding the null terminator
nullIndex := bytes.IndexByte(decompressed, 0)
header := string(decompressed[:nullIndex])
content := decompressed[nullIndex+1:]
parts := strings.Split(header, " ")
return parts[0], content, nil
}
Engineering Rationale:
- Path Reconstruction: The object path is reconstructed using the same sharding logic as
WriteObject, demonstrating the symmetric nature of the key-value store. - Decompression: The content must be decompressed from zlib format before it can be read. This is the inverse of the write operation.
- Header Parsing: The header is parsed to determine the object's type and size, which is then returned to the caller along with the raw content. This allows higher-level functions to know how to interpret the object's data.
Go Language Insights for Beginners
[]bytevs.string: In Go,[]byteis a mutable slice of bytes, which is the natural and efficient way to handle file I/O and binary data like compressed content.stringis an immutable sequence of bytes, typically used for text.sidgit-gocorrectly uses[]bytefor all file operations and conversions tostringare only done when necessary for display or parsing.fmt.Sprintf: A powerful function from thefmtpackage for creating formatted strings, used here to construct the object header with the correct type and length.zlibpackage: Part of Go's standard library, providing a simple and efficient interface for zlib compression and decompression, a core component of Git's storage format.deferstatement: Thedefer reader.Close()statement is a key feature of Go for resource management. It guarantees that thereader.Close()function will be called just before theReadObjectfunction returns, ensuring that resources are always released, even in the case of an error.
By understanding these two core functions, we have deconstructed the fundamental read/write operations of sidgit-go's content-addressed object store. This immutable, cryptographically-secure foundation is what makes the entire system trustworthy and robust.
Trees and the Index: From Files to Directory Snapshots
In the previous chapter, we explored how sidgit-go stores individual file contents as blob objects. However, a version control system must also track the relationships between files—specifically, the directory structure. This is the role of the tree object, a fundamental data structure in Git's object model.
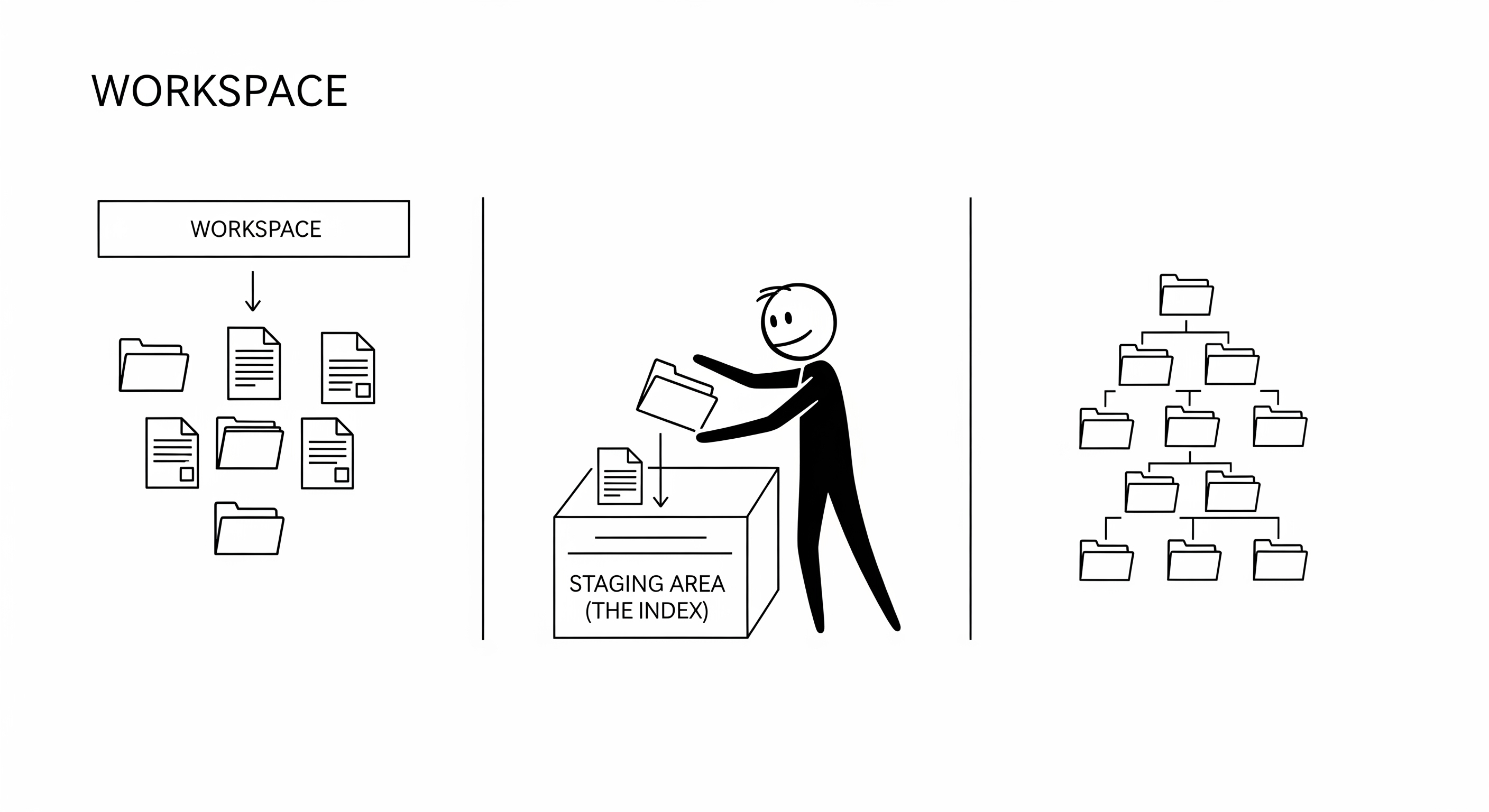
The tree Object: A Directory Snapshot
A tree object is a recursive data structure that represents a single directory at a specific point in time. It is a simple, sorted list of entries, where each entry contains:
- File Mode: A string representing the file's permissions (e.g.,
100644for a regular file,100755for an executable,040000for a directory). - Object Type:
blobfor files,treefor subdirectories. - SHA-1 Hash: The 20-byte SHA-1 hash of the associated
blobortreeobject. - Filename: The name of the file or directory.
This structure allows sidgit-go to represent the entire state of a repository by recursively traversing a single root tree. This design is highly efficient, as it allows for entire subdirectories to be shared between commits if they haven't changed.
The write-tree Command: Creating a Tree from the Index
The write-tree command reads the current state of the staging area (the index) and creates a tree object that represents it. This is a critical step in the commit process. Let's analyze the implementation from internal/cli/helpers.go.
The WriteTreeFromIndex Function
// internal/cli/helpers.go
func WriteTreeFromIndex(repo *git.Repository, entries []git.IndexEntry) (string, error) {
// 1. Build a nested map representing the directory structure
treeBuilder := make(map[string]interface{})
for _, entry := range entries {
parts := strings.Split(entry.Path, string(os.PathSeparator))
current := treeBuilder
for i, part := range parts {
if i == len(parts)-1 {
current[part] = entry
} else {
if _, ok := current[part]; !ok {
current[part] = make(map[string]interface{})
}
current = current[part].(map[string]interface{})
}
}
}
// 2. Recursively write tree objects
return writeTreeRecursive(repo, treeBuilder)
}
func writeTreeRecursive(repo *git.Repository, pathMap map[string]interface{}) (string, error) {
var treeContent []byte
var keys []string
for k := range pathMap {
keys = append(keys, k)
}
// 3. Sort entries lexicographically
sort.Strings(keys)
for _, path := range keys {
entry := pathMap[path]
var mode []byte
var sha1Hex string
var err error
switch v := entry.(type) {
case map[string]interface{}: // This is a subdirectory
sha1Hex, err = writeTreeRecursive(repo, v) // Recurse
if err != nil {
return "", err
}
mode = []byte("40000") // Directory mode
case git.IndexEntry: // This is a file
sha1Hex = v.SHA1
mode = []byte(v.Mode)
}
sha1Bytes, _ := hexDecode(sha1Hex)
// 4. Construct the tree entry line in binary format
entryLine := append(mode, ' ')
entryLine = append(entryLine, path...)
entryLine = append(entryLine, '\x00')
entryLine = append(entryLine, sha1Bytes...)
treeContent = append(treeContent, entryLine...)
}
// 5. Write the final tree object
return repo.WriteObject(treeContent, "tree")
}
Engineering Rationale:
- Nested Map Structure: The code first converts the flat list of index entries into a nested map (
map[string]interface{}) that mirrors the directory structure. This is a common and efficient way to represent a file tree in memory before serializing it. - Recursion: The
writeTreeRecursivefunction uses recursion to traverse the nested map and writetreeobjects for each subdirectory. This is a natural fit for the hierarchical nature of file systems and the recursive definition of thetreeobject. - Lexicographical Sorting: Sorting the tree entries by filename is critical. This ensures that the same directory content will always produce the same
treeobject hash, which is essential for data integrity and deduplication. Without this, two identical directory structures could produce different hashes. - Binary Format: The tree object content is a precise binary format, not a human-readable string. The SHA-1 hash is stored as 20 raw bytes, not a 40-character hex string. This is a performance optimization that reduces the size of tree objects and makes parsing faster.
The Index: Decoupling the Working Directory from the Repository
The index (or staging area) is a crucial component that often confuses new Git users. Its primary purpose is to decouple the working directory from the commit history. It is a file (.sidgit/index) that acts as a staging area for the next commit.
The ReadIndex and WriteIndex Functions
// internal/git/index.go
func (r *Repository) ReadIndex() ([]IndexEntry, error) {
// ... reads .sidgit/index and parses it into a slice of IndexEntry structs ...
}
func (r *Repository) WriteIndex(entries []IndexEntry) error {
// ... writes a slice of IndexEntry structs to .sidgit/index ...
}
Engineering Rationale:
- Decoupling: The index allows you to stage changes incrementally. You can modify 10 files in your working directory, but only
add2 of them to the index to be included in the next commit. This provides granular control over your commit history. - Performance: The index acts as a cache of the repository's state. When you run
git status, it compares the working directory to the index, which is much faster than comparing it to the entire commit history, which would require traversing the DAG and reading tree objects. - Conflict Resolution: During a merge, the index is used to store the different versions of conflicting files, providing a structured workspace for resolving conflicts.
Go Language Insights for Beginners
map[string]interface{}: This is a flexible map that can store values of any type. It's used here to build the nested directory structure, where a value can be either anIndexEntry(a file) or anothermap[string]interface{}(a subdirectory). This is a powerful feature of Go's type system, but should be used with care, as it requires type assertions to access the underlying values.- Type Assertion (
v.(type)): Theswitch v := entry.(type)statement is a Go type switch. It allows you to determine the concrete type of an interface value and execute different logic for each type. This is the idiomatic way to work withinterface{}types in Go. - Recursion: The
writeTreeRecursivefunction demonstrates how recursion can be used to solve problems that have a hierarchical structure, like traversing a file system tree. Go's support for recursion is efficient and a fundamental tool for many algorithms. - Binary Data Manipulation: The code demonstrates how to work with binary data in Go, including appending byte slices and converting hex strings to raw bytes. This is a common requirement in systems programming.
By understanding how tree objects and the index work, we can now see how sidgit-go builds a complete, cryptographically verifiable snapshot of the repository's state, which is the final prerequisite for creating a commit.
Commits, Pointers, and the Directed Acyclic Graph
We have now explored how sidgit-go stores file content (blob objects) and directory structures (tree objects). The final piece of the puzzle is the commit object, which ties these components together to form a coherent, historical record of the repository—a Directed Acyclic Graph (DAG).
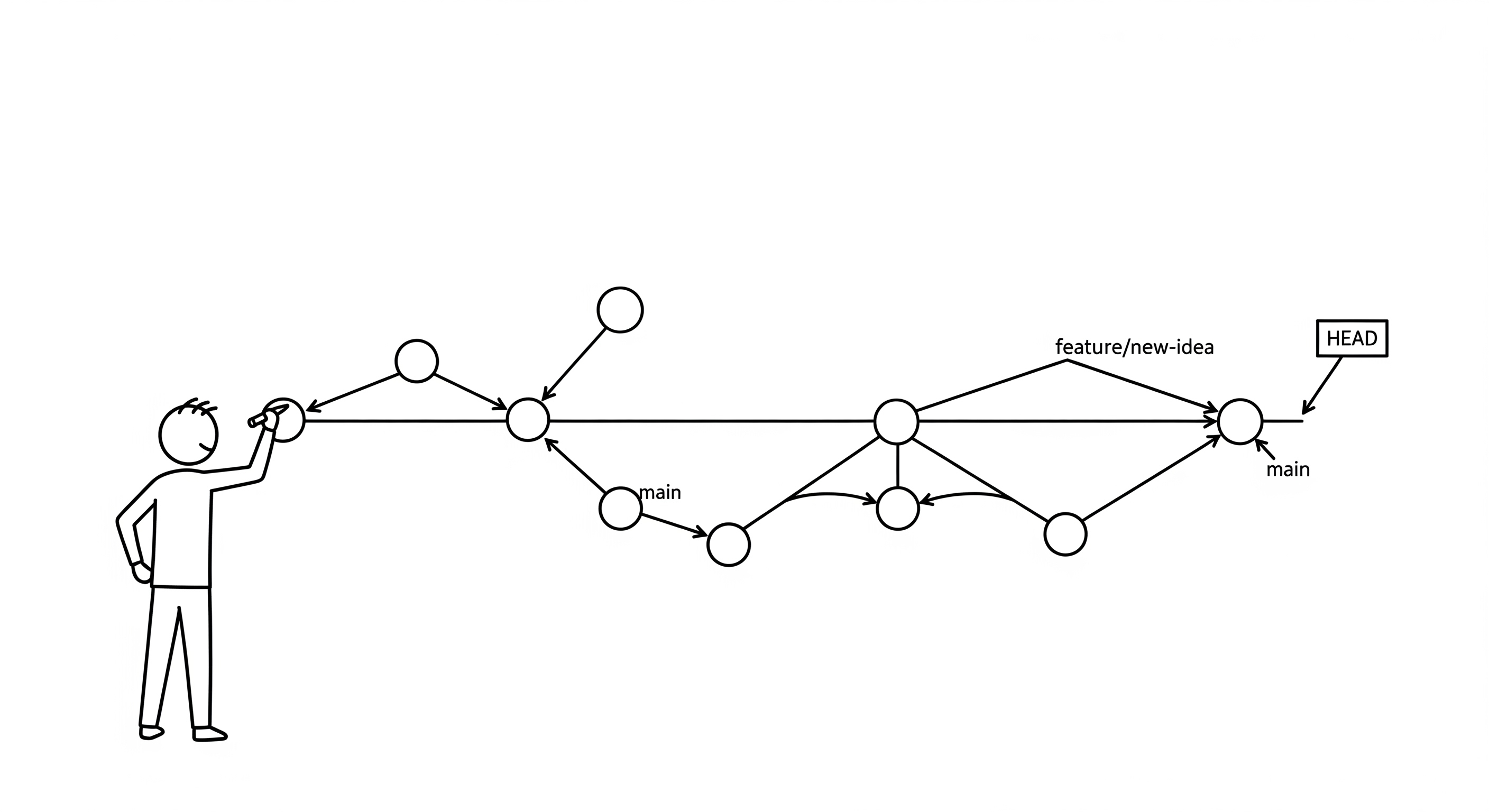
The commit Object: A Node in the History Graph
A commit object is a simple data structure that represents a single, immutable snapshot in the repository's history. It contains:
- A pointer to the root
treeobject, representing the complete state of the repository at that moment. - Pointers to one or more parent commits, forming the directed edges of the DAG.
- Author and committer metadata, including name, email, and a Unix timestamp.
- A commit message describing the changes.
The commit Command: Creating a Commit Object
The commit command is the final step in recording changes to the repository. It creates a commit object that points to the current root tree (from the index) and the previous commit (from HEAD). Let's analyze the implementation from internal/cli/handlers.go.
The HandleCommit Function
// internal/cli/handlers.go
func HandleCommit(args []string) {
// ... argument parsing ...
message := args[1]
repo, err := git.FindRepo(".")
// ... error handling ...
// 1. Write the tree from the index
entries, _ := repo.ReadIndex()
treeHash, _ := WriteTreeFromIndex(repo, entries)
// 2. Get the parent commit from the current branch's HEAD
ref, _ := repo.GetHeadRef()
parent, _ := repo.GetBranchCommit(ref)
// 3. Get author and committer metadata from environment variables
authorName := os.Getenv("GIT_AUTHOR_NAME")
// ... more metadata handling ...
// 4. Construct the commit object content as a string
var commitData strings.Builder
commitData.WriteString(fmt.Sprintf("tree %s\n", treeHash))
if parent != "" {
commitData.WriteString(fmt.Sprintf("parent %s\n", parent))
}
commitData.WriteString(fmt.Sprintf("author %s <%s> %d %s\n", authorName, authorEmail, timestamp, tz))
commitData.WriteString(fmt.Sprintf("committer %s <%s> %d %s\n", authorName, authorEmail, timestamp, tz))
commitData.WriteString(fmt.Sprintf("\n%s\n", message))
// 5. Write the commit object to the database
commitHash, _ := repo.WriteObject([]byte(commitData.String()), "commit")
// 6. Update the branch reference to point to the new commit
repo.UpdateBranch(ref, commitHash)
fmt.Printf("[%s %s] %s\n", strings.TrimPrefix(ref, "refs/heads/"), commitHash[:7], message)
}
Engineering Rationale:
- Write Tree First: The first step is always to create a
treeobject from the index. This ensures we have a single, immutable reference (SHA-1 hash) to the repository's state. - Parent Pointer: The parent commit is retrieved from the current branch's reference file. This is how the DAG is constructed, linking each commit to its predecessor(s).
- Metadata: Author and committer information is retrieved from environment variables, mirroring Git's behavior and allowing for system-level configuration.
- Commit Object Format: The commit object content is a simple, human-readable text format that is then hashed to create the commit's SHA-1. This makes it easy to debug and inspect the object store manually.
- Write Commit Object: The same
WriteObjectfunction is used to create the commit object, demonstrating the elegance of a unified object model. - Atomic Branch Update: The final, critical step is updating the branch reference. This is an atomic operation that moves the branch pointer from the parent commit to the new commit, effectively advancing the branch's history.
Branches and HEAD: The Power of Pointers
In Git-like systems, branches are not complex data structures; they are simply pointers—files that contain the SHA-1 hash of a commit. This is one of Git's most brilliant and efficient design decisions.
- Branches (
.sidgit/refs/heads/): Each file in this directory represents a branch. The file's name is the branch name (e.g.,main), and its content is the 40-character SHA-1 of the commit that the branch points to. HEAD(.sidgit/HEAD): This file is a symbolic reference. It usually contains a path to the current active branch (e.g.,ref: refs/heads/main). This is howsidgit-goknows which branch to update on a new commit. In a "detached HEAD" state, it can also contain a raw SHA-1 hash.
This pointer-based system is incredibly efficient. Creating a new branch is a single file write operation. Switching branches is a single file read and write operation. This is why branching and merging are so fast in Git.
Go Language Insights for Beginners
strings.Builder: This is a highly efficient way to build strings in Go. It avoids the performance overhead of repeated string concatenation by using a mutable byte buffer internally. This is the recommended approach for building strings of unknown length.- Environment Variables (
os.Getenv): Go provides easy access to environment variables, a common way for CLI tools to receive configuration without complex command-line parsing. - File I/O: The entire system is built on basic file I/O operations (
ioutil.ReadFile,ioutil.WriteFile,os.MkdirAll), demonstrating that a complex system like a VCS can be built on simple, fundamental primitives. The Go standard library provides all the necessary tools for this. - Error Handling: Notice the pattern of checking for
err != nilafter most function calls. This is the idiomatic way to handle errors in Go and ensures that the program fails gracefully when something goes wrong.
With the commit command, we have now implemented a complete, minimum viable version control system. We can initialize a repository, add files, and create a historical record of changes, all built on the robust foundation of the object store and the pointer-based history model.
Building a Commit Graph Visualizer
From Linear History to a Directed Acyclic Graph
A linear git log is sufficient for simple repositories, but it fails to convey the rich, non-linear history of a project with multiple branches. The log --graph feature of sidgit-go solves this by visualizing the repository's Directed Acyclic Graph (DAG) directly in the terminal. This chapter deconstructs the algorithms and data structures required to build this feature, a powerful example of how a CLI tool can provide a rich user experience.
The Challenge: Visualizing a DAG in an ASCII-Constrained Environment
The core engineering challenge is to transform the abstract, non-linear commit graph into a two-dimensional ASCII art representation that is both accurate and human-readable. This requires a sophisticated understanding of graph theory and careful attention to visual layout within the constraints of a terminal.
The Algorithm: A Multi-pass Approach
The implementation in internal/git/graph.go and internal/ui/graph_renderer.go uses a multi-pass algorithm, a common strategy for solving complex layout problems:
- Graph Construction: Build an in-memory representation of the commit graph from the raw object data.
- Topological Sort: Order the commits chronologically while respecting the parent-child relationships inherent in the DAG.
- Column Assignment: Assign each branch to a horizontal "lane" to minimize line crossing and create a clean visual flow.
- ASCII Rendering: Iterate through the sorted commits and draw the graph line by line, character by character.
Pass 1: Graph Construction
The BuildCommitGraph function traverses the repository's references to build a graph of CommitNode structs.
// internal/git/graph.go
func (r *Repository) BuildCommitGraph() (*CommitGraph, error) {
// 1. Get all branch heads from .sidgit/refs/heads
branches, _ := r.GetAllBranches()
// 2. Traverse from each branch head recursively
for _, branch := range branches {
// ... recursively build graph from commits ...
}
// 3. Link parent-child relationships in memory
// ...
return graph, nil
}
Key Insight: The graph is built by starting at the tips of the branches (the "heads") and walking backward through the parent pointers of each commit. This ensures that all reachable commits are included in the graph and that the relationships between them are correctly established.
Pass 2 & 3: Topological Sort and Column Assignment
This is the most algorithmically complex part of the feature. The commits must be sorted chronologically, but also in a way that allows for a clean visual layout.
// internal/git/graph.go
func (g *CommitGraph) TopologicalSort() []*CommitNode {
// ... implements Kahn's algorithm for topological sorting ...
}
func (g *CommitGraph) AssignColumns() {
// ... assigns each commit to a horizontal "lane" using a custom heuristic ...
}
Engineering Rationale:
- Topological Sort: A standard algorithm for ordering the nodes in a DAG. This ensures that a commit is always processed after its parents, which is crucial for correct rendering. Without this, the graph would be drawn out of order.
- Column Assignment: A custom heuristic algorithm that assigns each branch to a horizontal "lane." This is a greedy algorithm that attempts to minimize the crossing of lines in the final ASCII art, making the graph much easier to read. It's a classic graph drawing problem adapted for a terminal environment.
Pass 4: ASCII Rendering
The GraphRenderer in internal/ui/graph_renderer.go iterates through the sorted and positioned commits and draws the final output.
// internal/ui/graph_renderer.go
func (r *GraphRenderer) RenderGraph() string {
var result strings.Builder
sorted := r.graph.TopologicalSort()
for _, node := range sorted {
// 1. Render the graph line (|, *, /, \) based on column assignments
graphLine := r.RenderLine(node)
// 2. Render the commit info (hash, message, etc.)
commitInfo := r.RenderCommitInfo(node)
result.WriteString(fmt.Sprintf("%s %s\n", graphLine, commitInfo))
}
return result.String()
}
Engineering Rationale:
- Line-by-Line Rendering: The graph is drawn one commit (and one line of text) at a time. For each line, the renderer decides whether to draw a vertical line (
|), a commit marker (*), a merge line (/or\), or a space for each column. This is a stateful process that keeps track of active branches. - Color Coding: Each branch lane is assigned a different color from a predefined palette. This makes it easy to distinguish between different lines of development and follow the history of a particular branch.
Go Language Insights for Beginners
- Custom Data Structures: The
CommitNodeandCommitGraphstructs are custom data structures designed specifically for this problem.CommitNodecontains not just the commit data, but also pointers to its parents and children, and metadata for rendering (likeColumn). This demonstrates how to model complex relationships in Go. - Complex Algorithms: This feature demonstrates that Go is well-suited for implementing complex graph algorithms like topological sorting and custom heuristics for layout.
- Separation of Concerns: The graph-building logic (
internal/git) is completely separate from the rendering logic (internal/ui). This is a key principle of good software design that allows for independent development and testing of these components.
The log --graph feature is a powerful example of how a CLI tool can provide a rich, visual user experience by applying sophisticated algorithms to its underlying data structures. It transforms a simple list of commits into an insightful narrative of the project's history, revealing the true non-linear nature of software development.
Conclusion and Next Steps
Engineering SidGit: A Retrospective
Through this deconstruction of sidgit-go, we have not just built a Git clone; we have reverse-engineered the fundamental principles that underpin modern version control systems. By analyzing a production-ready codebase, we have moved beyond simple "how-to" instructions and into the realm of architectural and engineering rationale.
Core Engineering Principles Revisited:
-
Content-Addressing is the Immutable Foundation: The decision to use a content-addressed object store is the most critical architectural choice. It is the bedrock that provides cryptographic guarantees of data integrity, enabling efficient, deduplicated storage and a level of trust that is impossible with traditional, location-addressed file systems. Every other feature is built upon this foundation of immutability.
-
The DAG is the True History: We have seen that the history of a repository is not a linear timeline, but a Directed Acyclic Graph. Understanding this data structure is key to implementing complex, non-linear features like branching, merging, and graph visualization. The
log --graphfeature is a direct manifestation of this DAG structure. -
Pointers are a Lightweight, Powerful Abstraction: Branches and tags are not complex data structures, but simple pointers (files containing a SHA-1 hash) to commit objects. This elegant, minimalist design is what makes operations like branching and tagging incredibly lightweight and fast in Git. It is a masterclass in building powerful abstractions on top of simple primitives.
-
The Index as a Decoupling Mechanism: The staging area (index) is a powerful feature that decouples the working directory from the repository, allowing for granular control over what gets committed. It acts as a transactional buffer, a cache for status operations, and a conflict resolution workspace during merges.
-
Layered Architecture Enables Extensibility: By separating the system into distinct presentation, application, and core domain layers,
sidgit-goremains maintainable, testable, and extensible. This is the key to building a system that can evolve over time, whether that means adding a new command, a new network protocol, or a new user interface.
Go Language Reflections for Beginners:
- Go is a Systems Language: This project demonstrates Go's suitability for building high-performance, systems-level tools. Its strong typing, explicit error handling, simple concurrency model, and powerful standard library make it an ideal choice for this domain.
- The Standard Library is Your Most Powerful Tool: Many of the core features of
sidgit-go(file I/O, zlib compression, SHA-1 hashing, string manipulation) were implemented using only Go's standard library. Mastering the standard library is the most direct path to becoming a proficient Go engineer. - Structs and Interfaces are for Modeling: Custom data structures like
CommitNodeandRepositoryare essential for modeling the problem domain effectively. Interfaces allow for clean decoupling between layers, while structs provide a way to organize complex data.
Next Steps and Future Engineering Challenges
sidgit-go is a powerful tool, but it is by no means complete. Here are several potential enhancements that would make excellent follow-up projects for any engineer looking to deepen their understanding of distributed systems.
1. Implement Three-Way Merges
- Challenge: The current implementation only supports fast-forward merges. A proper three-way merge requires finding a common ancestor between two branches (the "merge base") and applying a more complex, three-way diff algorithm.
- Key Concepts: Lowest Common Ancestor (LCA) algorithms, diff3, conflict resolution strategies.
2. Add Remote Operations (push, pull, clone)
- Challenge: This would require implementing a network protocol (likely HTTP or a custom TCP protocol) for transferring Git objects between repositories. This involves serializing objects, creating efficient "packfiles" to minimize network traffic, and handling authentication.
- Key Concepts: Network programming, serialization, packfiles, smart HTTP protocol.
3. Support Tag Objects
- Challenge: The current architecture has a placeholder for
tagobjects. This would involve creating a new object type for annotated, GPG-signed tags and implementing thetagcommand. - Key Concepts: Object model extension, reference management, cryptography (GPG integration).
4. Performance Optimizations with Packfiles
- Challenge: For very large repositories, reading and parsing individual, zlib-compressed objects can be slow due to the high number of file system operations. Git solves this with
packfiles, which bundle many objects into a single, highly compressed file with an accompanying index. - Key Concepts: File formats, data compression, indexing, delta compression.
5. Build and Deploy the Web Visualizer
- Challenge: Take the
visualizer-uifrom a local tool to a fully deployed web application on a platform like Vercel or Netlify. This would involve building a more robust API and considering the security implications of a public-facing service. - Key Concepts: Web development (Next.js), APIs, file system access patterns, security sandboxing.
This guide has provided a blueprint for understanding the core of a version control system. The true learning comes from extending it. Choose one of these challenges, and continue your journey into the art of engineering distributed systems.